The LLM Shield: How to Build Production-Grade NSFW Guardrails for AI Agents
Content moderation is one of the most critical yet challenging aspects of building AI applications. As developers, we’re tasked with creating systems that can understand context, detect harmful content, and make nuanced decisions—all while maintaining a positive user experience. Today, I want to share insights from building a production-grade NSFW detection system that goes beyond simple keyword blocking.
Why Simple Keyword Filtering Isn’t Enough
When I first started working on content moderation, I thought a simple blocklist would suffice. Flag a few explicit words, block them, and call it a day. Reality quickly proved me wrong.
Users are creative. They use character substitutions (“s3x”), deliberate spacing (“p o r n”), and roleplay scenarios to bypass filters. Meanwhile, legitimate medical and educational content was getting incorrectly flagged. The system needed to be smarter—it needed context awareness.
The Multi-Layered Approach
The solution I developed uses a four-tier severity classification system, inspired by industry standards from organizations like OpenAI and Microsoft. Here’s how it breaks down:
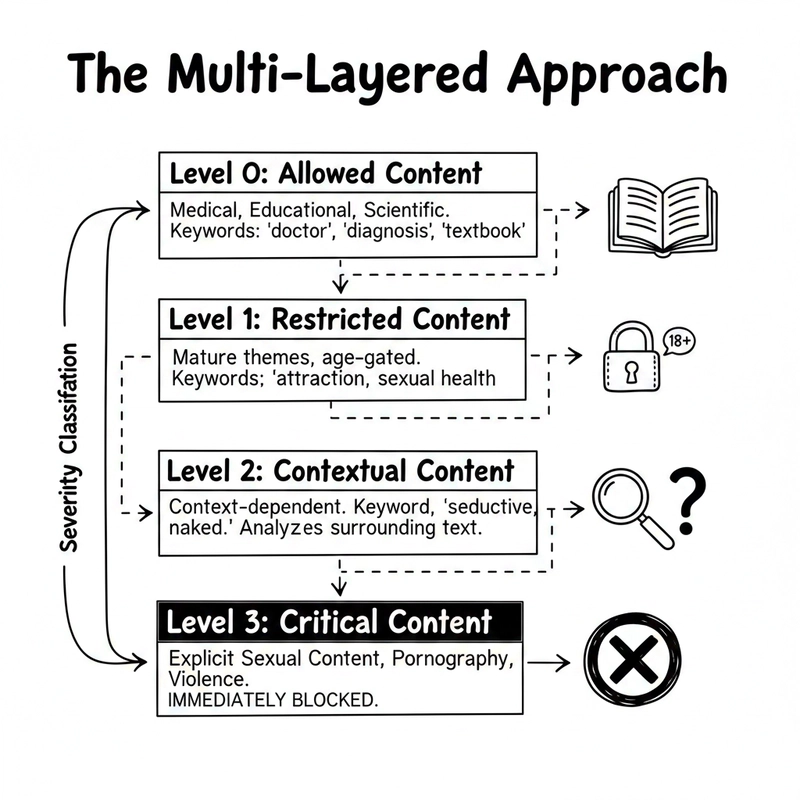
Level 0: Allowed Content
This includes medical, educational, and scientific content. Think anatomy textbooks, reproductive health articles, or clinical research papers. The system looks for contextual indicators like “doctor,” “diagnosis,” “textbook,” or “peer-reviewed” to identify this category.
Level 1: Restricted Content
Mature themes that aren’t explicitly sexual but may require age verification. This includes content about kissing, attraction, or sexual health education. It’s the gray area that needs careful handling.
Level 2: Contextual Content
This is where things get interesting. Terms like “aroused,” “seductive,” or “naked” can be perfectly appropriate in some contexts (art history, literature analysis) but inappropriate in others. The system analyzes surrounding text to make informed decisions.
Level 3: Critical Content
Explicit sexual content, pornographic material, and sexual violence. This gets blocked immediately, no questions asked. The patterns here are carefully designed to catch both direct language and obfuscated attempts.
Detecting Jailbreak Attempts
One pattern I’ve seen repeatedly is users trying to bypass filters through roleplay: “Let’s pretend we’re characters in a story where…” The system specifically watches for roleplay indicators combined with sexual content, treating these as high-risk attempts to circumvent protections.
Handling Obfuscation
Users employ various tricks to evade detection:
Character separation: “p.o.r.n” or “s-e-x”
Deliberate misspellings: “p0rn” or “s3xy”
Leetspeak substitutions: “nak3d” or “h0rny”
Obfuscation Patterns
Character separation:
p[._-]?o[._-]?r[._-]?n
Leetspeak:
p[o0]rn
s[e3]x
h[o0]rny
The obfuscation detector uses regex patterns that account for these variations. It looks for suspicious patterns like excessive punctuation between characters or common number-for-letter substitutions.
The Ensemble Decision Engine
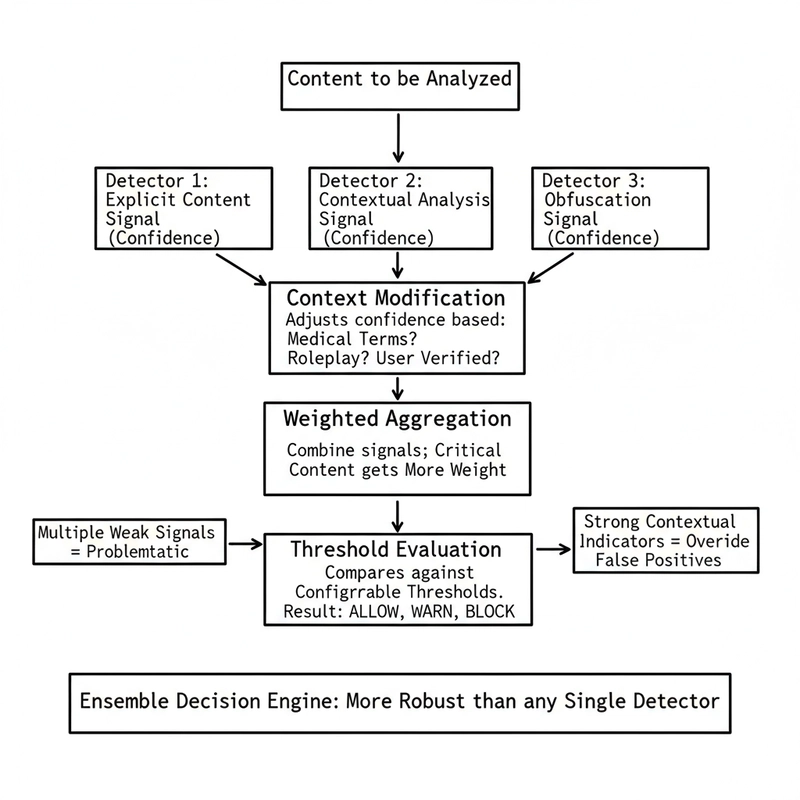
Here’s where all the pieces come together. When content is analyzed:
- Signal Collection: Each detector (explicit content, contextual analysis, obfuscation) generates a signal with a confidence score
- Context Modification: The base confidence is adjusted based on context (medical terms present? roleplay detected? user verified?)
- Weighted Aggregation: Signals are combined, with critical content getting more weight
- Threshold Evaluation: The final decision compares against configurable thresholds
if severity_scores[L3] > 0:
action = BLOCK
elif severity_scores[L2] > threshold:
action = WARN or BLOCK
elif severity_scores[L1] > threshold:
action = ALLOW or WARN
else:
action = ALLOW
This ensemble approach is more robust than any single detector. Multiple weak signals can combine to indicate problematic content, while strong contextual indicators can override false positives.
Practical Implementation Considerations
Configuration Flexibility
Real-world applications need different strictness levels. The system supports three preset configurations:
Strict Mode: For general audience apps. Blocks Level 1+ content with a low confidence threshold (0.6). Best for platforms accessible to minors.
Age-Verified Mode: For adult platforms with user verification. Allows Level 1 content and requires higher confidence (0.7) before blocking Level 2 content.
Educational Mode: Optimized for academic settings. Only blocks Level 3 critical content and uses a high threshold (0.8) to minimize false positives on legitimate educational material.
Custom Rules
Every application has unique needs. The system allows:
- Custom blocklists: Add domain-specific terms that should always block
- Custom allowlists: Override detections for known safe terms in your context
- Confidence thresholds: Adjust how aggressive the filtering should be
Transparency and Auditability
One crucial aspect often overlooked is transparency. When content is blocked, users deserve to understand why. The system provides detailed metadata:
Severity level and confidence score
Specific signals that triggered detection
Which patterns were matched (without exposing the full pattern library)
Whether the content appears to be in an educational/medical context
This transparency helps with:
- User trust: People can understand and potentially appeal decisions
- Debugging: Developers can identify false positives
- Compliance: Audit trails for regulatory requirements
Future Enhancements
Content moderation is an evolving challenge. Some areas for future development:
Machine Learning Integration: Pattern-based detection has limits. ML models can learn nuanced patterns and adapt to new evasion techniques.
Multi-Language Support: The current system is English-focused. Expanding to other languages requires language-specific patterns and cultural context awareness.
Image and Video: Text is just the beginning. Visual content moderation adds another dimension of complexity.
User Feedback Loop: Allow users to report false positives/negatives, feeding improvements back into the system.
Conclusion
Building effective content moderation requires balancing multiple competing goals: safety, accuracy, user experience, and performance. A multi-layered approach with context awareness provides the flexibility to handle diverse scenarios while maintaining high accuracy.
The key takeaways:
- Simple keyword blocking fails in production environments
- Context analysis is essential for reducing false positives
- Multiple detection signals provide robustness
- Configuration flexibility allows adaptation to different use cases
- Transparency builds user trust
Content moderation isn’t a solved problem—it’s an ongoing challenge that requires continuous refinement. But with thoughtful architecture and careful implementation, we can build systems that protect users while respecting legitimate content.
If you’re building AI applications with user-generated content, I hope this guide provides a solid foundation for your moderation strategy. The code and patterns discussed here are based on real-world production experience and industry best practices.
Github Code : https://github.com/aayush598/agnoguard/blob/main/src/agnoguard/guardrails/nsfw_advanced.py
Stay safe, and happy coding!
Have questions about implementing NSFW detection in your application? Found this guide helpful? Leave a comment below or connect with me on your preferred platform. I’d love to hear about your experiences with content moderation.
