Simple Chunking Approaches: Fixed-Size and Recursive Methods
This is a cross-post, you can find the original article on my Medium
Simple chunking is a fundamental technique for breaking large documents into smaller, manageable pieces without losing important context. In this guide, we’ll explore practical approaches including sliding window chunking and recursive chunking, comparing their strengths and weaknesses.
Fixed-Size Methods
Consider the following document:
document = """
John Doe is the CEO of ExampleCorp.
He's a skilled software engineer with a focus on scalable systems.
In his spare time, he plays guitar and reads science fiction.
ExampleCorp was founded in 2020 and is based in San Francisco.
It builds AI solutions for various industries.
John still finds time for music and books, even with a busy schedule.
The company is a subsidiary of Example Inc, a tech conglomerate.
Example Inc started in 2015 and is headquartered in New York.
ExampleCorp keeps its startup energy despite the parent company.
San Francisco and New York serve as the main hubs.
This supports talent on both coasts.
John's mix of tech and creativity shapes a forward-thinking culture.
"""
How could we split this document into digestible chunks?
The simplest way to chunk a document is to use fixed-size chunking.
This method is relatively simple: we split the document into chunks of a fixed size.
Here is how the implementation looks like:
def fixed_size_chunking(document, chunk_size):
return [document[i:i+chunk_size] for i in range(0, len(document), chunk_size)]
chunks = fixed_size_chunking(document, 100)
The issue with this approach is that it will split the document at arbitrary points.
For example, here are the first three chunks of our example document:
"nJohn Doe is the CEO of ExampleCorp.nHe's a skilled software engineer with a focus on scalable syste"
'ms.nIn his spare time, he plays guitar and reads science fiction.nnExampleCorp was founded in 2020 a'
'nd is based in San Francisco.nIt builds AI solutions for various industries.nJohn still finds time f'
Note how the word “systems” is split between the first and second chunk.
With longer documents, this will become a big problem as we will split context between chunks and lose important information.
A straightforward improvement to fixed-size chunking is sliding window chunking where each new chunk slides forward while retaining some overlap with the previous chunk.
This allows us to retain some context between the chunks.
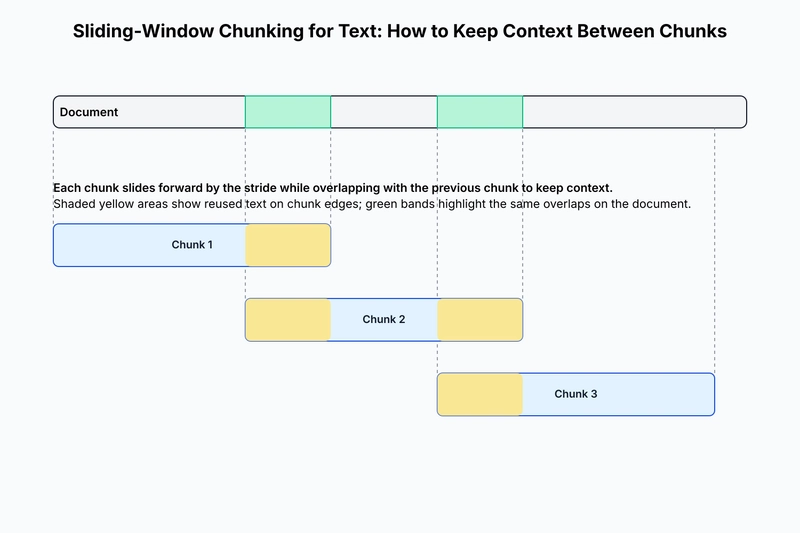
Here is how the implementation looks like:
def sliding_window_chunking(document, chunk_size, overlap):
chunks = []
for i in range(0, len(document), chunk_size - overlap):
chunks.append(document[i:i+chunk_size])
return chunks
chunks = sliding_window_chunking(document, 100, 20)
Here are the first three chunks:
"nJohn Doe is the CEO of ExampleCorp.nHe's a skilled software engineer with a focus on scalable syste"
'us on scalable systems.nIn his spare time, he plays guitar and reads science fiction.nnExampleCorp w'
'tion.nnExampleCorp was founded in 2020 and is based in San Francisco.nIt builds AI solutions for var'
This is slightly better, but still not great.
The problem with both of these approaches is that they are not aware of the content of the document.
They will always split the document at the same place regardless of the actual document structure.
Recursive Chunking
A more sophisticated approach is to use recursive chunking where we define a hierarchy of separators and use them to recursively split the document into smaller chunks.
For instance, we might prioritize separators in the following order:
- Paragraphs (split by
nn) - Sentences (split by
.) - Sentence parts (split by
,)
We can then use this hierarchy to recursively split the document into smaller chunks where we first split by the coarsest separator and then move to the finer ones until the chunks are below a certain size.
Here is how the function signature would look like:
def recursive_chunking(text, separators, max_len):
...
How could we implement this?
First, we would need to define the base case—if the text is already short enough, or there no more separators left, we just return the current text as a chunk:
if len(text) <= max_len or not separators:
return [text]
Assuming the base case is not met, we proceed with the recursive case by selecting the first (i.e., highest-priority) separator and splitting the text accordingly:
sep = separators[0]
parts = text.split(sep)
Now, we have a list of parts and we can iterate over each part and check whether it is still too long.
If that is the case, then we should recursively chunk the part again with the remaining separators.
Otherwise, we can just add the part to the list of chunks.
We also need to make sure that we skip empty parts.
This approach follows a classic recursive structure and can be implemented as follows:
for part in parts:
if not part.strip():
continue # Skip empty parts
# If still too long, recurse with other separators
if len(part) > max_len and len(separators) > 1:
chunks.extend(recursive_chunking(part, separators[1:], max_len))
# Otherwise, we can just add the part to the list of chunks
else:
chunks.append(part)
Finally, we need to return the list of chunks from the recursive function.
Here is how the entire function implementation looks like:
def recursive_chunking(text, separators, max_len):
if len(text) <= max_len or not separators:
return [text]
sep = separators[0]
parts = text.split(sep)
chunks = []
for part in parts:
if not part.strip():
continue # Skip empty parts
# If still too long, recurse with other separators
if len(part) > max_len and len(separators) > 1:
chunks.extend(recursive_chunking(part, separators[1:], max_len))
else:
chunks.append(part)
return chunks
chunks = recursive_chunking(document, ['nn', '.', ','], 100)
Here are the first three chunks:
'nJohn Doe is the CEO of ExampleCorp'
"nHe's a skilled software engineer with a focus on scalable systems"
'nIn his spare time, he plays guitar and reads science fiction'
Much better.
Generally speaking, it is often useful to take document structure into account when performing chunking, especially when working with structured document formats such as Markdown or HTML.
For example, if we have a Markdown document, we can use the headers to split it into sections.
Consider the following Markdown document:
# A Markdown Document
## Introduction
This is the introduction of the document.
## Background
This is the background section of the document.
## Conclusion
This is the conclusion of the document.
We can use the headers to split the document into sections:
def markdown_chunking(document):
return document.split("nn##")
chunks = markdown_chunking(document)
A real implementation would be more complex and might account for headings of different levels, code blocks, and other constructs.
Additionally, combining Markdown chunking with recursive chunking can produce more granular chunks.
When documents are cleanly structured, simple chunking strategies can be highly effective.
However, structure alone is not enough.
While these methods recognize the document’s syntax, they cannot capture its meaning.
This can be solved by utilizing semantic chunking, which will be the topic of another post.
If you found this helpful, drop a ❤️ and hit Follow to get more dev insights in your feed!