GB/s Level Editable DOM JSON Engine: The Architectural Philosophy Behind LJSON
Project Address: https://github.com/lengjingzju/json
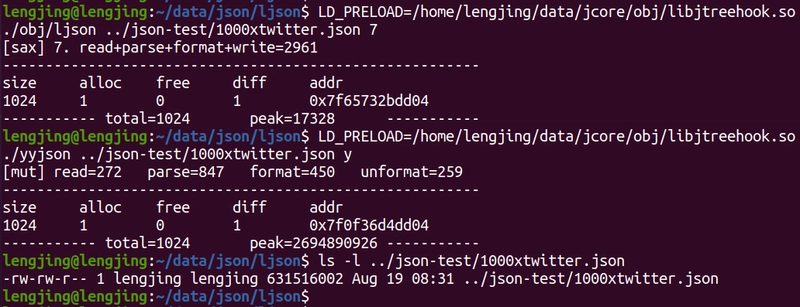
LJSON Reuse Mode(editable DOM) Parsing Tested 1000 Times (2.3 GB/s) (Test Platform: PC | CPU: Intel i7-1260P | OS: Ubuntu 20.04 (VMWare))

SAX Stream Mode, The memory usage of LJSON is constant (17328 Bytes)
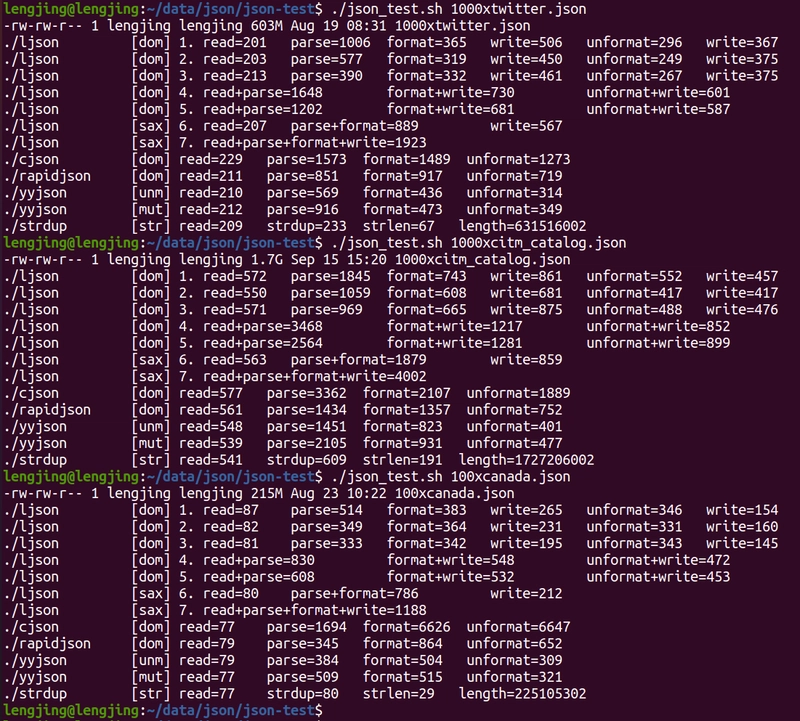
Performance Comparison of Big Json File
Introduction: Redefining High-Performance JSON Processing
In the realm of C language JSON libraries, the performance race never stops. Born in October 2019, a full year earlier than yyjson, LJSON was designed not merely to pursue extreme parsing speed in benchmarks, but to find the optimal balance between performance, memory usage, editability, streaming capability, and maintainability.
This fundamental difference in design philosophy can be perfectly illustrated by the analogy of Space Shuttle (LJSON) versus Rocket (yyjson/simdjson).
The current state of LJSON is remarkable:
- Performance that matches or even surpasses yyjson in most scenarios
- Provides true streaming processing capability that yyjson’s architecture cannot achieve
- Maintains code readability and extensibility, suitable for long-term evolution
This article delves into the architectural philosophy, performance optimization strategies of LJSON, and its fundamental differences with yyjson, revealing the design wisdom behind a versatile JSON engine.
I. Core Capabilities: Dual-Engine Drive
All-Purpose JSON Processing
- Full support for JSON5 specification (hexadecimal, comments, trailing commas, single quotes, etc.) (some features require manual enabling)
- DOM / SAX dual parsing modes
- True streaming file processing (parse while reading, print while writing)
High-Performance Numeric Conversion Engine
- Innovative ldouble algorithm
- Float ↔ string conversion performance far exceeds standard library algorithms and mainstream algorithms (sprintf, grisu2, dragonbox)
- Precision set to 16 decimal digits, boundary handling pursues the shortest representation rather than mechanical even rounding
II. Architectural Design: Multi-Mode Adaptation for Full Scenarios
LJSON provides 7 parsing modes and 4 printing modes, forming a complete solution system:
Parsing Modes
- DOM Classic Mode (malloc/free) – Basic choice for general scenarios
- DOM Memory Pool Mode (unified application and release of large memory blocks) – Reduces memory fragmentation, improves allocation efficiency
- DOM Reuse Mode (editable, in-place string reuse) – Maximizes memory utilization
- DOM File Stream Mode (true streaming) – Powerful tool for large file processing
- DOM File Stream Memory Pool Mode (true streaming + memory pool) – Combination of streaming processing and memory management
- SAX Mode (callback processing) – Efficient event-driven parsing
- SAX File Stream Mode (true streaming + callback) – Ultimate solution for large file event processing
Printing Modes
- DOM → String – Standard serialization output
- DOM → File (true streaming) – Large JSON file generation
- SAX → String – Efficient conversion from event stream to string
- SAX → File (true streaming) – Efficient output from event stream to file
True Streaming: Parse while reading the file, print while writing the file, without needing to read the entire file or generate large intermediate buffers. Memory usage can be reduced to a constant level, requiring only KB-level memory even when processing 1GB JSON files.
yyjson ≈ LJSON’s DOM Reuse Mode + Aggressive Read-Only Optimization
III. The Balanced Approach to High-Performance Optimization in LJSON: Philosophical Thinking and Engineering Practice
This chapter does not cover architecture-specific optimizations (e.g., assembly, SIMD, etc.), nor system-wide optimizations (e.g., multithreading, asynchronous notifications, etc.).
Introduction: A Deep Dialogue with the Essence of Computing
Performance optimization is neither pure technical stacking nor abstract metaphysical speculation, but a profound dialogue with the essence of computing. It requires developers to find the art of dynamic balance between limited resources and infinite possibilities, between time and space, between ideal and reality. The optimization practice of the LJSON project is based on three cornerstones: “respecting the essence of data, embracing hardware characteristics, and simplifying hot-path decisions,” organically integrating philosophical thinking with engineering feasibility.
True performance breakthroughs stem from insights into the nature of data, compliance with hardware characteristics, and respect for engineering laws. Through innovative architectural design and algorithm optimization, LJSON has achieved breakthrough performance improvements in the field of JSON processing, all built on a profound engineering philosophy.
1. Algorithms and Frameworks: The Wise Balance of Multi-Dimensional Parsing Modes
Philosophical Thinking
The ultimate boundary of all optimization is defined by algorithms and frameworks. This is about choice – finding the path that best fits the constraints among infinite solution spaces; it is also about constraints – acknowledging the finiteness of resources and building order under this premise. The foundation of high performance begins with insight into the essence of the problem, not with patching up minor details. An elegant algorithm is built on a deep abstraction of the problem; a powerful framework stems from successful encapsulation of complexity.
Excellent developers know how to identify, among the infinite possibilities of the problem space, the solution that best matches hardware characteristics, data features, and business requirements, seeking the optimal interpretation in the three-dimensional space formed by “problem scale—time complexity—space complexity.” This choice is not only a technical decision but also a deep insight into the essence of the problem.
LJSON’s design philosophy is to provide rich functionality while ensuring that each scenario can match the optimal parsing path.
Practical Principles
The LJSON framework provides up to 7 parsing modes and 4 printing modes, forming a complete solution system. This multi-mode architecture embodies the engineering philosophy of “no absolute optimum, only the most suitable,” enabling developers to choose the most appropriate processing strategy based on specific scenarios.
2. Lookup Table Method: Extreme Optimization in Limited Domains
Philosophical Thinking
The lookup table method embodies the basic philosophy of time-space conversion: trading spatial determinism for temporal uncertainty. By precomputing and storing possible results, complex runtime calculations are converted into efficient memory access. Its essence lies in identifying operations with limited input domains but high computational costs, trading space for time to achieve performance leaps.
Practical Principles
LJSON applies lookup table optimization in multiple critical paths:
- Character type judgment: Use compact lookup tables to quickly identify character types (e.g., whitespace, digits, etc.), avoiding expensive branches
- Escape character processing: Precompute escape sequences and special character mappings to accelerate string serialization and deserialization
- Number parsing and serialization: Design dedicated lookup tables for floating-point, large number, division, and other operations, reducing real-time computation
These optimizations are strictly limited to finite domains, ensuring that the table structures are compact and cache-friendly. LJSON’s lookup table strategy always adheres to “small and refined,” with each table carefully designed to run efficiently in L1/L2 cache.
3. Reducing Data Copying: Maintaining Order and Reducing Entropy
Philosophical Thinking
Unnecessary copying is an “entropy increase” process in software systems, leading to resource waste and energy inefficiency. The way to optimize lies in practicing entropy reduction – by passing references (essence) rather than copies (appearance), maintaining the simplicity and order of the system. Cherish the form and flow of data, avoiding unnecessary movement and replication. Zero-copy is the ideal embodiment of this philosophy, allowing data to flow naturally along its inherent track, like a river rushing along its channel.
Practical Principles
LJSON minimizes data copying through multiple techniques:
- In-place string reuse: In DOM reuse mode, string data is directly reused in the original buffer, avoiding copying
- Direct buffer operation: Parsing/printing results are generated directly in the target buffer, eliminating intermediate steps
- Pointer optimization strategy: Use pointers instead of value copies for large structures, reducing memory movement overhead
- Zero-copy parsing: Directly reference input data in supported scenarios without copying
These measures together form the core of LJSON’s efficient memory management, ensuring minimal data movement overhead in various scenarios.
4. Information Recording Optimization: Precomputation and Intelligent Prediction
Philosophical Thinking
The wisdom of optimization lies not in avoiding computation, but in avoiding repeated computation. LJSON, through a fine-grained information recording mechanism, saves the results of a single computation and uses them multiple times, reflecting a deep respect for computational resources.
Practical Principles
LJSON implements information recording optimization at multiple levels:
-
String metadata recording:
- Record string length to avoid repeated strlen execution
- Record escape status to optimize serialization performance
- Cache hash values to accelerate dictionary lookup
-
Resource precomputation:
- Preallocate memory resources based on file size
- Allocate sufficient buffers in advance to avoid frequent malloc
-
State persistence:
- Record the state of storage buffers for parsing and printing
- Achieve zero heap allocation mode through buffer reuse, eliminating runtime memory allocation
This strategy enables LJSON to achieve deterministic performance in most scenarios, avoiding the uncertainty brought by runtime computation.
5. Batch Operations: Transforming Fragmentation into Integrated Performance Improvement
Philosophical Thinking
The bottleneck of modern systems often stems from the overhead of processing massive fragmented operations. Batch operations are a rebellion against fragmentation, advocating integration and batch processing, transforming random requests into smooth flows, following dissipative structure theory, using order to combat chaos.
Practical Principles
LJSON improves performance through multiple batch processing techniques:
-
Memory pool management:
- Provide optional memory pool allocators to replace frequent malloc/free, reduce fragmentation, and improve cache locality
- Estimate and allocate large blocks of memory at once, with fine-grained internal management
-
Buffered IO optimization:
- File stream mode adopts large-block reading strategy to reduce system call times
- When writing, buffer first and then write in batches to maximize IO throughput
-
Batch memory operations:
- Use memcpy/memmove instead of byte-by-byte copying
- Design code structures that facilitate compiler vectorization to leverage modern CPU advantages
These techniques enable LJSON to maintain excellent performance even when processing large-scale data.
6. Precision and Engineering Balance: Innovative Practice of the ldouble Algorithm
Philosophical Thinking
The obsession with absolute precision is the perfectionism of idealism, while engineering is essentially the art of trade-offs. In reality, what we often pursue is not the mathematically optimal solution, but a satisfactory solution under constraints – actively giving up negligible precision can exchange great savings in computation, bandwidth, and energy consumption.
Practical Principles
LJSON’s self-developed ldouble algorithm embodies the fine balance between precision and performance:
-
Precision strategy:
- Adopt 16 decimal digits of precision, meeting the needs of most scenarios
- Boundary handling pursues the shortest representation, not mechanical even rounding
-
Performance optimization:
- Avoid expensive division, large number, and floating-point operations
- Optimize common number processing paths
This algorithm significantly improves performance while still ensuring sufficient precision and reliability.
7. Branch Prediction Optimization: Dancing with Uncertainty
Philosophical Thinking
The CPU pipeline craves determinism, and conditional branches are its challenge. Branch prediction optimization is humans injecting probability and patterns into hardware, teaching it to “guess,” thus dancing with uncertainty. The likely/unlikely macros are “prior knowledge” passed by humans to the compiler, a prophecy about execution probability.
Practical Principles
LJSON adopts various strategies in branch prediction optimization:
- Hot path priority: Place the most common conditions first to improve prediction accuracy
- Branch elimination: Use bit operations and mathematical identities to replace branches
- Data-driven: Convert conditional judgments into lookup table operations to reduce the number of branches
- Loop optimization: Simplify loop conditions to improve prediction efficiency
- Branch selection: Carefully choose between switch-case and if-else
These optimizations ensure that LJSON fully unleashes the potential of modern CPU pipelines on critical paths.
8. Cache Hit Optimization: The Art of Data Locality
Philosophical Thinking
Cache optimization is based on the application of the principles of temporal and spatial locality: temporal locality (revisit soon) and spatial locality (access nearby) are the keys to drive storage hierarchy. Optimizing cache hits is a carefully orchestrated art of data layout. It requires organizing information from the CPU’s perspective – not the human perspective – shaping an efficient and hardware-compatible “spatial aesthetics.”
Practical Principles
LJSON employs various cache optimization techniques:
-
Data structure optimization:
- Compress object size, e.g., optimize JSON Object from 48 bytes to 32 bytes (64-bit system)
- Reorder fields to reduce padding bytes and improve cache line utilization
-
Code layout optimization:
- Place hotspot code together to improve instruction cache efficiency
- Separate cold code into independent areas to reduce cache pollution
-
Loop optimization:
- Keep loop structures compact
- Optimize access patterns to enhance data locality
- Manually unroll loops for some hotspot functions
-
Memory access optimization:
- Prioritize sequential access to maximize cache line utilization
- Reduce random access to improve hardware prefetching results
These optimizations together ensure that LJSON achieves near-optimal performance at the memory access level.
9. Inlining and Function Reordering: The Spatiotemporal Weaving Art of Code
Philosophical Thinking
Inlining breaks the physical boundaries of functions, a spatial weaving art – weaving code segments into the calling context to eliminate call overhead. Function reordering (PGO) is a temporal weaving art – based on the actual profile, physically arranging frequently consecutively executed functions closely together.
Both point to one thing: the physical layout of code should work in concert with its execution context, achieving efficient spatiotemporal unity.
Practical Principles
- Selective inlining: Only inline small hotspot functions to reduce call overhead
- PGO optimization: Use profile feedback to optimize function layout
- Modular inlining: Keep function responsibilities single to facilitate compiler decisions
- Avoid over-inlining: Prevent code bloat and instruction cache pollution
IV. Design Philosophy Differences with yyjson
The core differences reflect different engineering philosophies:
| Dimension | LJSON | yyjson |
|---|---|---|
| Mode Design | Multi-mode (incl. true streaming, editable reuse) | Single reuse mode (read-only optimized) |
| Editability | Reuse mode is editable | Read-only and editable strictly separated (val / mut_val) |
| String Storage | Standard C string (trailing 1 �) |
Non-standard trailing 4 � (reduces boundary checks) |
| Object Storage | key and value stored together | key and value stored separately |
| Memory Strategy | On-demand allocation | Large block pre-allocation, high redundancy |
| Access Acceleration |
json_items_t cache, array O(1), object O(logN) |
Unknown if cached, possibly O(N)/O(2N) |
| Optimization Techniques | Inlining, branch prediction, lookup tables, caching metadata, hotspot loop unrolling; Maintains readability | Similar optimizations + extensive macro loop unrolling, obscure code |
| Streaming Processing | True streaming parsing/printing | Not supported |
| Code Readability | High (clear structure, ~8k lines of code) | Very low (macro-intensive, ~20k lines of code) |
V. Performance Comparison and Real-World Scenario Performance
Optimization Technique Comparison
Both use:
- Algorithm optimization
- Memory pool (block) optimization
- Inlining optimization (inline)
- Branch prediction optimization (likely/unlikely)
- Cache hit optimization
- Lookup table optimization
- Copy optimization
- Information recording optimization (caching string length, etc.)
Differences:
-
yyjson: Extensive use of macros for manual loop unrolling, compact but obscure code, more aggressive performance; uses non-standard features (trailing 4
�, unaligned access, etc.). - LJSON: Pursues an engineering balance of maintainability, extensibility, low footprint, and high performance. Maintains readability; only unrolls loops for hotspot functions.
Actual Performance
- yyjson read-only reuse mode performance is slightly higher than LJSON, originating from a single pattern, aggressive resource utilization, non-standard features, and macro loop expansion
- yyjson read-only mode performance is very close to LJSON, with each winning in some cases
- yyjson editable mode performance may be significantly lower than LJSON (large file parsing: yyjson uses about twice the memory and is about half the speed of LJSON)
Note: If LJSON abandoned streaming, standard strings, and editability, and adopted more obscure code, it could achieve the performance of yyjson’s read-only reuse mode, but that would no longer be LJSON’s design philosophy.
VI. Comprehensive Multi-Dimensional Comparison
| Comparison Dimension | LJSON | yyjson | RapidJSON | cJSON |
|---|---|---|---|---|
| Parsing Performance | High (editable reuse) | Medium-High (editable) | Relatively High | Medium |
| Printing Performance | High (true streaming + ldouble) | High (full buffering) | Medium | Low |
| Memory Usage | Can be constant-level (streaming) | Relatively High | Relatively High | Relatively High |
| CPU Feature Dependency | Low | Low | Medium | Low |
| Extensibility | High | Low | Medium | High |
| Code Readability | High | Very Low | Medium | High |
| Key Mechanisms | Zero heap allocation, memory pool reuse, in-place strings, json_items, ldouble | In-place reuse, memory blocks, non-standard string tails, loop unrolling | Templates+allocators | malloc/free |
VII. Applicable Scenarios and Selection Suggestions
- Large File Processing: GB-level JSON formatting/compression, memory usage can be constant-level → LJSON Streaming Mode
- Embedded Systems: Low memory, high performance requirements → LJSON Memory Pool Mode
- High-Frequency Read/Write: Real-time data stream parsing and generation → LJSON Editable Reuse Mode
- Extreme Read-Only Parsing: Extreme performance requirements and no need for editing → yyjson Read-Only Mode
- Cross-Platform Development: Linux / Windows / Embedded RTOS → LJSON (Pure C, zero dependencies)
Conclusion: The Balance of Performance and Engineering Art
LJSON’s optimization practice reveals a profound engineering truth: high performance does not stem from the extreme pursuit of a single technology, but from the art of the best balance between multiple dimensions. Truly excellent system optimization requires finding harmony between the micro and macro, short-term and long-term, human and machine.
In algorithm selection, LJSON does not pursue theoretical optimal complexity but seeks the most practical solution in real scenarios; in memory management, it does not pursue absolute zero-copy but weighs copy cost against implementation complexity; in precision handling, it does not pursue mathematical perfection but balances precision and efficiency based on needs.
yyjson is a sharp scalpel, focusing on the extreme performance of read-only parsing; while LJSON is a complete toolbox, balancing performance, flexibility, and maintainability. yyjson’s success lies in its deep polishing of a single mode, but its architecture is essentially just a specialized version within LJSON’s multi-mode system.
The real value of LJSON lies in its ability to stably support diverse JSON processing needs in real engineering environments with extremely low memory usage and high performance. It tells us that the highest state of optimization is not to make a single indicator perfect, but to make the entire system achieve a harmonious and efficient state in the real environment.
When selecting, developers should weigh the actual scenario: is it the extreme speed of read-only parsing, or the architectural flexibility of general processing? Understanding the essential differences between the two is key to making truly engineered decisions.

