EdgeBERT: I Built My Own Neural Network Inference Engine in Rust
Lightweight BERT Embeddings in Rust (Sentence-Transformers Alternative Without Python)
I needed semantic search in my Rust app, so users could search for “doctor” and still find documents mentioning “physician” or “medical practitioner”. I wanted a lightweight BERT embeddings solution in Rust, small enough to run on edge devices, browsers, and servers without headaches.
The trick is to turn text into vectors that capture meaning. Similar words → similar numbers.
-
doctor→ [0.2, 0.5, -0.1, 0.8, …] -
physician→ [0.2, 0.4, -0.1, 0.7, …] ✅ similar -
banana→ [0.9, -0.3, 0.6, -0.2, …] ❌ different
The Pain with Existing Solutions
To compare it with Python, the standard approach is… heavy:
Just to generate embeddings, a fresh virtual environment ballooned to 6.8 GB, mostly PyTorch, tokenizers, and model weights.
The ONNX Runtime
But i was using Rust, someone mentioned ort, i’ll use ONNX Runtime from Rust. How hard could it be?
pub fn new(model_path: &str, tokenizer_path: &str) -> Result<Self> {
let environment = ort::environment::init()
.with_execution_providers([CUDAExecutionProvider::default().build()]).commit()?;
}
// ... 150 lines total just to get encode to work
Binary bloat
In the end it worked, but ort pulled in 80+ crates, expanded my release build to 350 MB, and relied on system libraries like libstdc++, libpthread, libm, libc. OpenSSL version mismatches added another headache.
System library conflicts
error: OpenSSL 3.3 required
$ openssl version
OpenSSL 1.1.1k # Can't upgrade - would break RHEL dependencies
The C++ dependencies wanted OpenSSL 3.3. My RHEL system had 1.1. Removing 1.1 would break half my system.
In the beginning i was trying to build a light-weight offline RAG solution, with this one dependency turned into a major challenge.
What i actually wanted
This was the API i was looking for
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(texts)
The Solution
So I built it my own inference engine in Rust:
use edgebert::{Model, ModelType};
let model = Model::from_pretrained(ModelType::MiniLML6V2)?;
let embeddings = model.encode(texts, true)?;
- 5MB binary
- 200MB RAM
- No dependencies hell
- Same accuracy (0.9997 correlation)
- BLAS optional feature flag
Performance
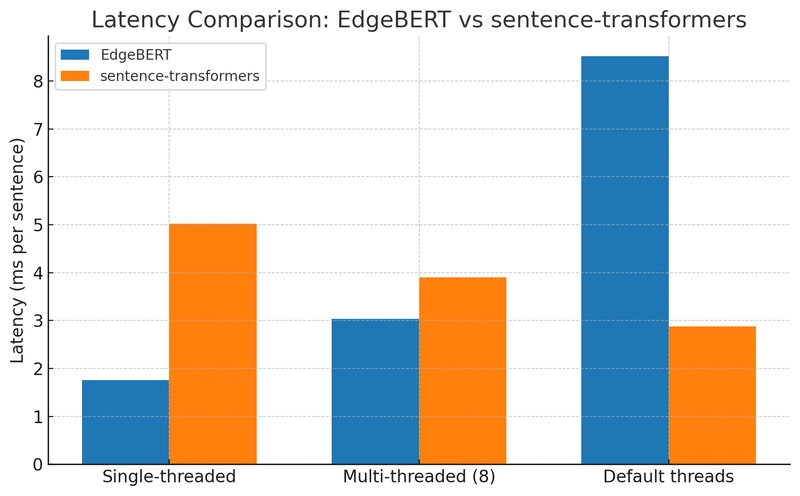
Initial benchmarks were promising, and after optimizing the matrix multiplication routines, here’s how EdgeBERT stacks up against sentence-transformers on a CPU:
| Configuration | EdgeBERT | sentence-transformers |
|---|---|---|
| Single-threaded | 1.76ms/sentence |
5.02ms/sentence |
| Multi-threaded (8) | 3.04ms/sentence | 3.90ms/sentence |
| Default threads | 8.52ms/sentence | 2.88ms/sentence |
👉 EdgeBERT is up to 3× faster in single-threaded scenarios. This is because MiniLM’s matrices (384×384) are small, meaning the overhead from thread coordination can outweigh the benefits of parallelization. While sentence-transformers pulls ahead when using all cores on large batches, EdgeBERT’s single-threaded efficiency is a key advantage for lightweight and edge applications.
CPU performance is only half the story. Memory efficiency, especially RAM usage during encoding, is critical. We can see a significant difference here:
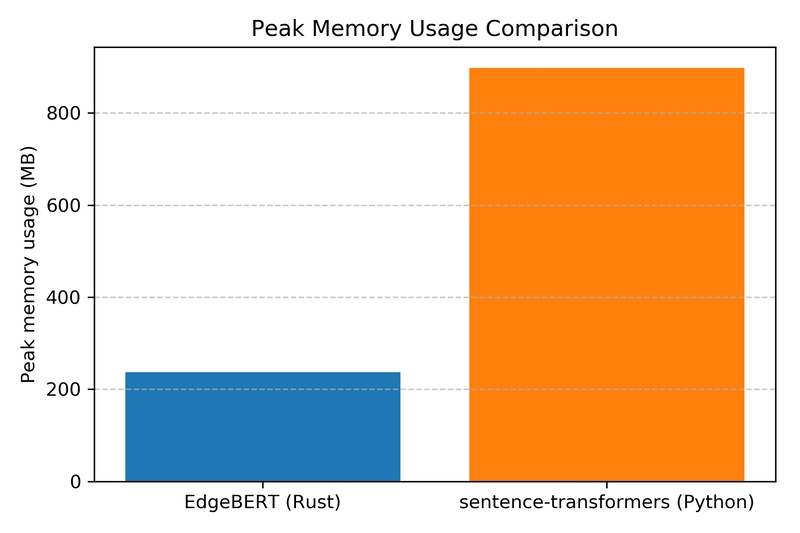
EdgeBERT’s memory footprint is not only smaller but also more stable, avoiding the large initial allocation spikes seen with the PyTorch-based solution.
Accuracy
Comparing with Python sentence-transformers:
EdgeBERT: [-0.0344, 0.0309, 0.0067, 0.0261, -0.0394, ...]
Python: [-0.0345, 0.0310, 0.0067, 0.0261, -0.0394, ...]
Cosine similarity: **0.9997**
Rounding differences of floating point computations, 99.97% the same.
Why This Matters (Even If You Don’t Do ML)
This enables:
- Smart search: Users find what they mean, not just what they typed
- Better recommendations: “If you liked X, you’ll like Y” based on meaning
- Duplicate detection: Find similar issues/documents even with different wording
- Content moderation: Detect harmful content regardless of phrasing
- RAG/AI features: Give LLMs the right context without keyword matching
All in 5MB of Rust. No Python required.
When to Use
Use EdgeBERT when:
- You need embeddings without Python
- Deployment size matters (5MB vs 6.8GB)
- Running on edge devices or browsers
- Memory is constrained
- Single-threaded performance matters
Use sentence-transformers when:
- You need GPU acceleration
- Using multiple model architectures
- Already in Python ecosystem
- Need the full Hugging Face stack
WebAssembly
Since it’s pure Rust with minimal dependencies, it compiles to WASM:
import init, { WasmModel, WasmModelType } from './pkg/edgebert.js';
const model = await WasmModel.from_type(WasmModelType.MiniLML6V2);
const embeddings = model.encode(texts, true);
429KB WASM binary + 30MB model weights. Runs in browsers.
Had to implement WordPiece tokenizer from scratch – the tokenizers crate has C dependencies that don’t compile to WASM.
How It Works
BERT is matrix operations in a specific order:
- Tokenization – WordPiece tokens to IDs
- Embedding – 384-dimensional vectors (word + position + segment)
- Self-attention – Q·K^T/√d, softmax, multiply by V
- Feed-forward – Linear, GELU, Linear
- Pooling – Average tokens into sentence embedding
Each transformer layer repeats attention and feed-forward, refining the representations. MiniLM has 6 layers.
The core implementation is ~500 lines in src/lib.rs.
No magic, just the transformer algorithm, written in Rust.
https://github.com/olafurjohannsson/edgebert
Configuration
For best performance:
# EdgeBERT - fastest single-threaded
export OPENBLAS_NUM_THREADS=1; cargo run --release --features openblas
# Python - let it auto-tune threads
python native.py
Installation
[dependencies]
edgebert = "0.3.4"
Roadmap & Future Work
EdgeBERT is focused and minimal by design, but there are exciting directions for the future:
- GPU Support: Adding wgpu support for cross-platform GPU acceleration is a top priority.
- More Architectures: Expanding beyond all-MiniLM-L6-v2 to support other efficient models.
- Quantization: Implementing model quantization to further reduce model size and improve performance on CPU and microcontrollers.
Pull requests are always welcome!
Code
https://github.com/olafurjohannsson/edgebert
Most of the implementation is in one file. Pull requests welcome.
I built this because I needed it.
I’m sharing it because maybe you do too. 🚀
Benchmark Details
- EdgeBERT:
cargo run --release --features openblas --bin nativewithOPENBLAS_NUM_THREADSset - Python:
python native.pywithOMP_NUM_THREADSset - Installed sentence_transformers using pip in a venv and inspected filesize du -sh venv/lib/python*/site-packages/
- Inspected Rust dependencies with cargo tree | wc -l
- Inspected venv dependencies pip list | wc -l
- WASM file size ls -lh examples/pkg/edgebert_bg.wasm
- Native file size ls -lh target/release/native
- Used /usr/bin/time -v to measure peak Maximum resident set size (kbytes)

