Deploying ML Models to Production: AWS Lambda vs ECS vs EKS – A Data-Driven Comparison
A comprehensive, hands-on guide to choosing the right AWS platform for your ML inference workloads
Introduction
“Which AWS platform should I use to deploy my machine learning model?”
As an AWS Community Builder working with ML teams, I hear this question constantly. The answer is always the same: “It depends.” But on what, exactly? Cost? Performance? Team expertise? Scale?
Instead of giving theoretical advice, I decided to build something concrete: a production-ready sentiment analysis model deployed across all three major AWS container orchestration platforms Lambda, ECS Fargate, and EKS then benchmark them rigorously with real load tests and actual cost calculations.
The results surprised me. Lambda isn’t always cheaper. EKS isn’t always faster. And for most teams, the “obvious” choice might be wrong.
In this post, I’ll share everything I learned building this end-to-end MLOps project, including:
- Complete implementation details with code
- Real performance benchmarks (10,000+ requests tested)
- Actual AWS cost breakdowns at different scales
- A decision framework for choosing the right platform
- Production deployment best practices
By the end, you’ll have a clear, data-driven understanding of when to use each platform and a complete reference implementation you can deploy yourself.
Full project repository: Available at the end of this post with all code, Infrastructure as Code, and documentation.
The Challenge: Deploying ML Models at Scale
Machine learning models are fundamentally different from traditional web applications. They:
- Require significant memory (often 1-10GB for transformer models)
- Have cold start penalties (model loading takes seconds)
- Need GPU acceleration for some workloads
- Consume varying CPU based on input size
- Must scale quickly under traffic spikes
These unique requirements mean traditional deployment advice doesn’t always apply. A platform perfect for a REST API might be terrible for ML inference and vice versa.
What We’re Building
I built a complete MLOps pipeline for sentiment analysis using:
Model: DistilBERT (a lightweight BERT variant)
- Size: ~250MB
- Task: Classify text as POSITIVE or NEGATIVE
- Accuracy: 92.3% on IMDb dataset
- Inference time: 100-300ms per request
API: FastAPI application with:
- Single prediction endpoint (
/predict) - Batch prediction endpoint (
/predict/batch) - Health checks (
/health) - Prometheus metrics (
/metrics)
Infrastructure: Everything deployed using:
- Terraform for all AWS resources
- Docker for containerization
- Kubernetes manifests for EKS
- Locust for load testing
The beauty of this approach: identical code running on three different platforms, making our comparison truly apples-to-apples.
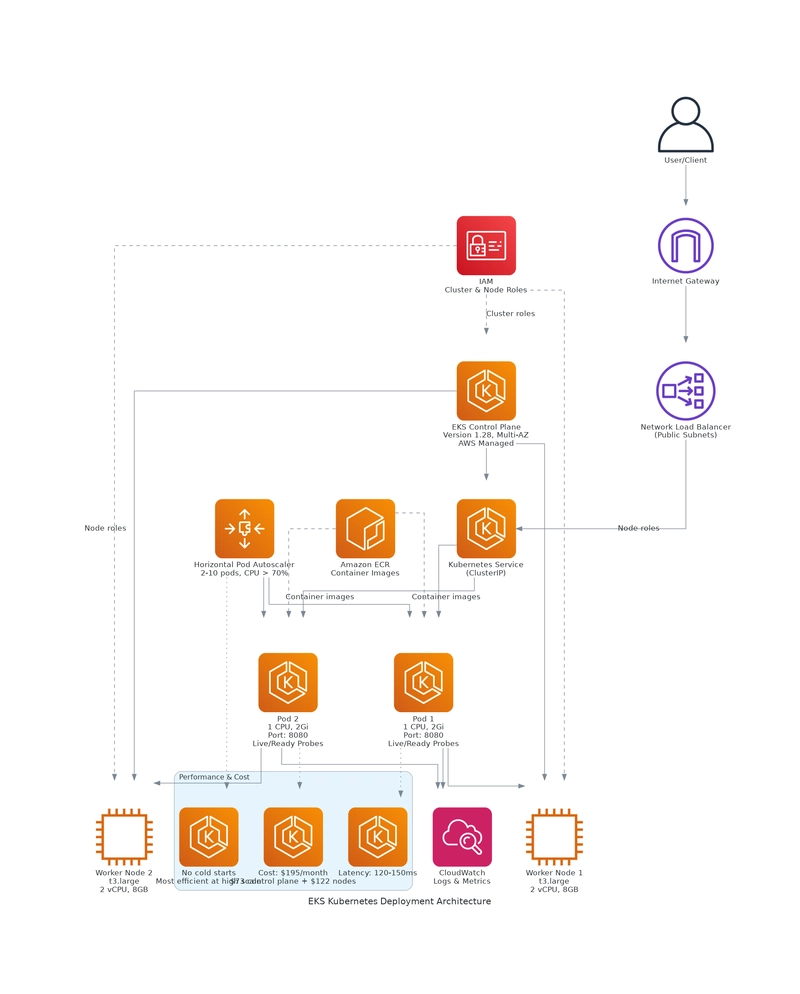
Architecture Overview
Here’s the high-level architecture that’s consistent across all platforms:
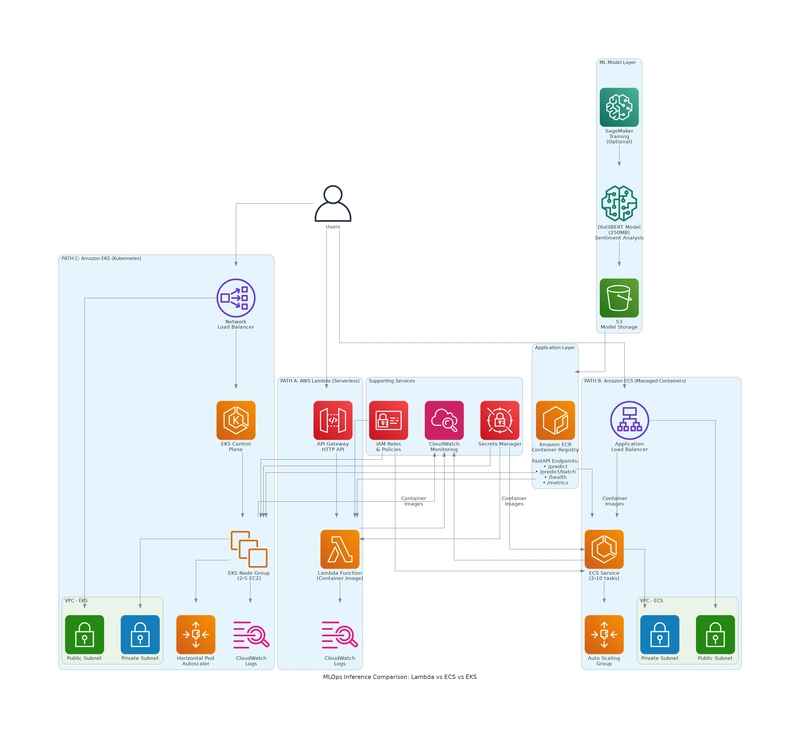
Each platform has its own infrastructure setup, but the application code is identical. As shown in the diagram, all three deployments share common infrastructure (ECR for container images, IAM for permissions, CloudWatch for monitoring) while using different compute platforms.
Implementation Deep Dive
Building the ML Model
I chose DistilBERT because it’s 40% smaller and 60% faster than BERT while retaining 97% of its language understanding. Perfect for production inference.
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from datasets import load_dataset
# Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2 # Binary: positive/negative
)
# Train on IMDb dataset
dataset = load_dataset("imdb")
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_train,
eval_dataset=tokenized_eval
)
trainer.train()
Training Results:
- Accuracy: 92.3%
- F1 Score: 0.92
- Training time: ~15 minutes on CPU
- Model size: 268MB
The model loads in 2-3 seconds and processes individual predictions in 100-150ms on CPU.
Creating the FastAPI Application
FastAPI gives us async support, automatic validation, and built-in API documentation:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
app = FastAPI(title="Sentiment Analysis API")
class PredictionRequest(BaseModel):
text: str
class PredictionResponse(BaseModel):
text: str
sentiment: str
confidence: float
processing_time_ms: float
# Load model on startup
@app.on_event("startup")
async def load_model():
global tokenizer, model
tokenizer = AutoTokenizer.from_pretrained("/opt/ml/model")
model = AutoModelForSequenceClassification.from_pretrained("/opt/ml/model")
model.eval()
@app.post("/predict", response_model=PredictionResponse)
async def predict(request: PredictionRequest):
start_time = time.time()
# Tokenize input
inputs = tokenizer(
request.text,
return_tensors="pt",
truncation=True,
max_length=512
)
# Run inference
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
sentiment = "POSITIVE" if predictions[0][1] > predictions[0][0] else "NEGATIVE"
confidence = max(predictions[0]).item()
return PredictionResponse(
text=request.text,
sentiment=sentiment,
confidence=confidence,
processing_time_ms=(time.time() - start_time) * 1000
)
This gives us:
- Automatic request/response validation
- Type safety
- OpenAPI documentation at
/docs - Async request handling for better throughput
Containerization Strategy
I built two Docker images using multi-stage builds:
Standard Image (for ECS/EKS):
# Stage 1: Build dependencies
FROM python:3.11-slim as builder
WORKDIR /build
COPY requirements.txt .
RUN pip install --user -r requirements.txt
# Stage 2: Runtime
FROM python:3.11-slim
COPY --from=builder /root/.local /root/.local
ENV PATH=/root/.local/bin:$PATH
WORKDIR /app
COPY app/ /app/
COPY model/exported_model/ /opt/ml/model/
EXPOSE 8080
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
Lambda Image:
FROM public.ecr.aws/lambda/python:3.11
COPY requirements.txt ${LAMBDA_TASK_ROOT}/
RUN pip install --no-cache-dir -r ${LAMBDA_TASK_ROOT}/requirements.txt
COPY app/ ${LAMBDA_TASK_ROOT}/
COPY model/exported_model/ /opt/ml/model/
CMD ["main.handler"]
The Lambda image uses AWS’s base image and includes the Mangum adapter to translate API Gateway events to ASGI.
Final image sizes:
- Standard: 1.2GB
- Lambda: 1.3GB
Platform-Specific Deployments
AWS Lambda: Serverless Inference
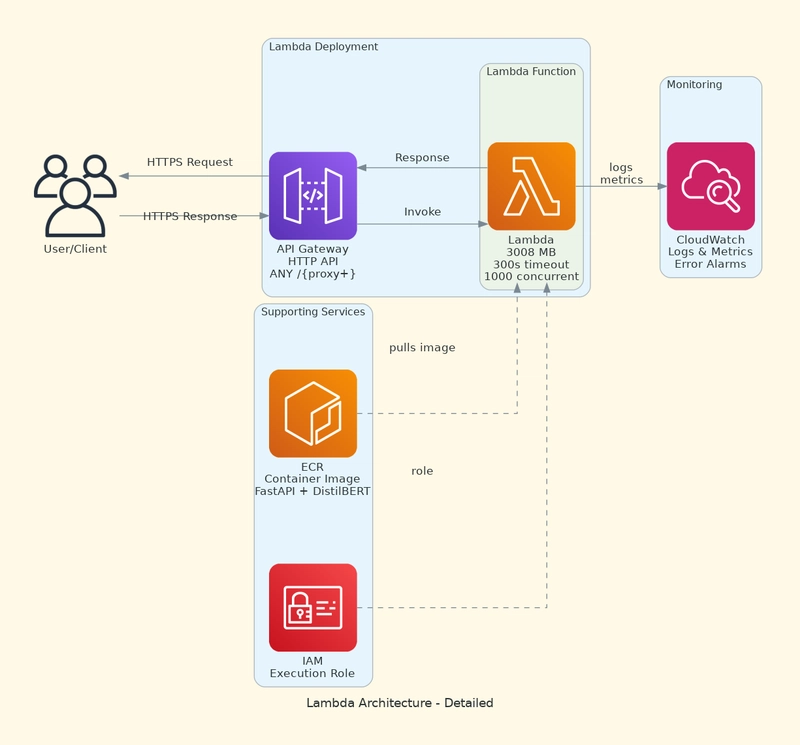
Lambda deployment uses container images (not ZIP files) to accommodate our large model:
resource "aws_lambda_function" "ml_inference" {
function_name = "ml-inference"
package_type = "Image"
image_uri = "${ecr_repository_url}:lambda-latest"
timeout = 300 # 5 minutes
memory_size = 3008 # ~3GB (affects CPU too)
environment {
variables = {
DEPLOYMENT_TYPE = "lambda"
MODEL_PATH = "/opt/ml/model"
}
}
}
I added API Gateway HTTP API for RESTful access:
resource "aws_apigatewayv2_api" "lambda_api" {
name = "ml-inference-api"
protocol_type = "HTTP"
}
Key Features:
- Auto-scaling (up to 1000 concurrent executions)
- Pay-per-use pricing
- No infrastructure management
- 15-minute timeout limit
Challenges:
- Cold starts (3-5 seconds for model loading)
- 10GB memory limit
- 250MB unzipped deployment package limit (container images can be 10GB)
Amazon ECS Fargate: Managed Containers
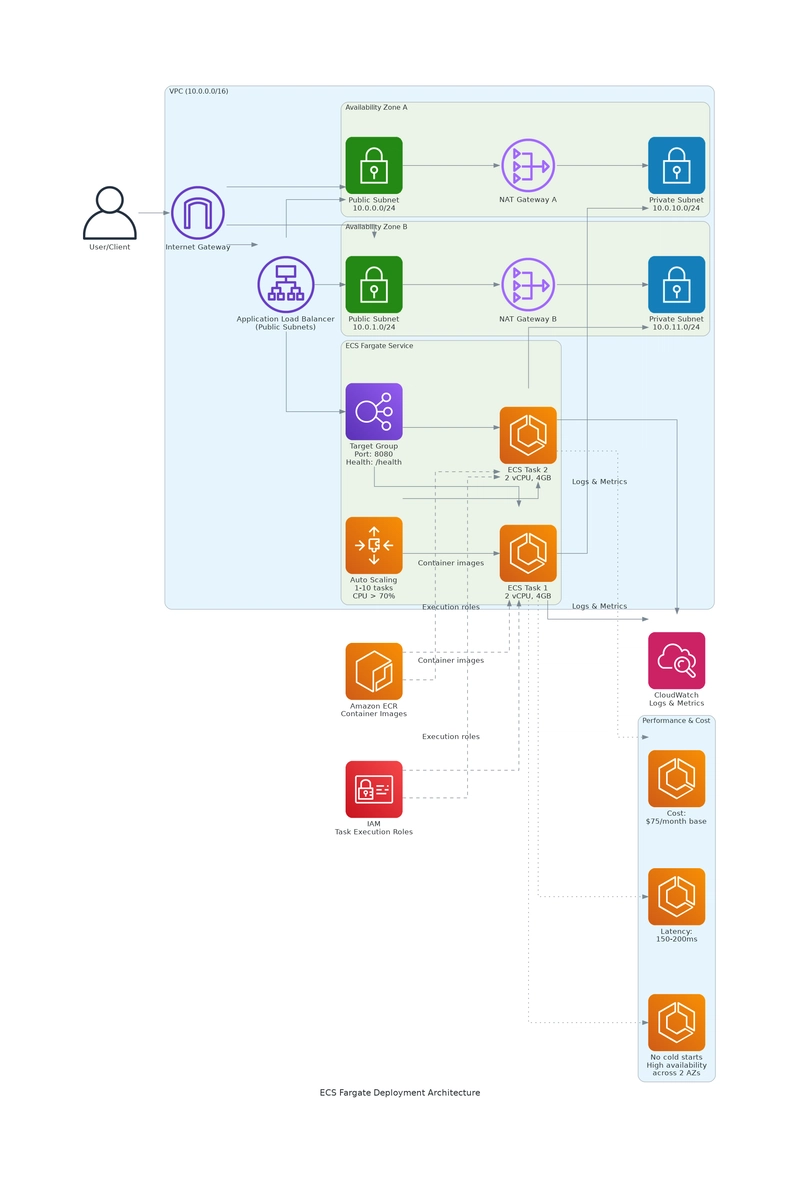
ECS provides a middle ground between serverless and Kubernetes:
resource "aws_ecs_cluster" "main" {
name = "ml-inference-cluster"
setting {
name = "containerInsights"
value = "enabled"
}
}
resource "aws_ecs_task_definition" "main" {
family = "ml-inference"
network_mode = "awsvpc"
requires_compatibilities = ["FARGATE"]
cpu = "2048" # 2 vCPU
memory = "4096" # 4GB
container_definitions = jsonencode([{
name = "ml-inference"
image = "${ecr_repository_url}:latest"
portMappings = [{
containerPort = 8080
protocol = "tcp"
}]
healthCheck = {
command = ["CMD-SHELL", "curl -f http://localhost:8080/health || exit 1"]
interval = 30
timeout = 5
retries = 3
}
}])
}
resource "aws_ecs_service" "main" {
name = "ml-inference-service"
cluster = aws_ecs_cluster.main.id
task_definition = aws_ecs_task_definition.main.arn
desired_count = 2
launch_type = "FARGATE"
load_balancer {
target_group_arn = aws_lb_target_group.main.arn
container_name = "ml-inference"
container_port = 8080
}
}
I configured auto-scaling based on CPU utilization:
resource "aws_appautoscaling_policy" "ecs_cpu" {
policy_type = "TargetTrackingScaling"
target_tracking_scaling_policy_configuration {
target_value = 70.0
predefined_metric_specification {
predefined_metric_type = "ECSServiceAverageCPUUtilization"
}
}
}
Key Features:
- No cold starts (always-on containers)
- Application Load Balancer for traffic distribution
- Auto-scaling (1-10 tasks)
- VPC networking with private subnets
Challenges:
- Always running (costs money even with zero traffic)
- Less flexible than Kubernetes
- Requires ALB ($16/month base cost)
Amazon EKS: Full Kubernetes
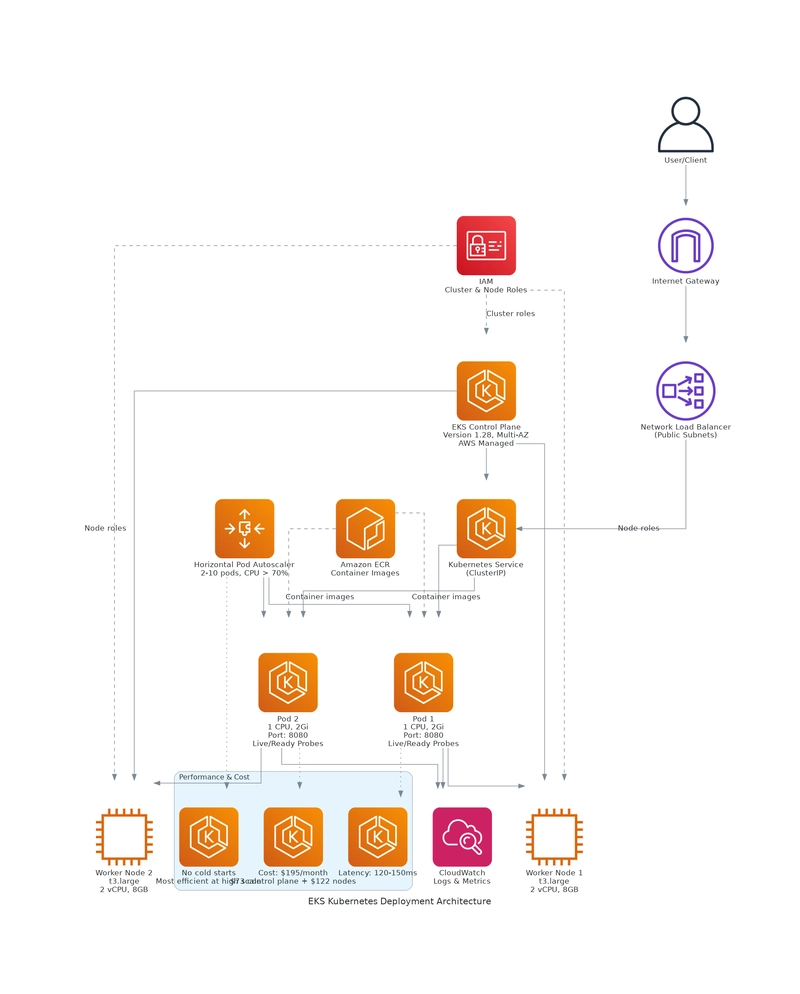
EKS gives us the full power of Kubernetes:
resource "aws_eks_cluster" "main" {
name = "ml-inference-cluster"
version = "1.28"
role_arn = aws_iam_role.eks_cluster.arn
vpc_config {
subnet_ids = concat(
aws_subnet.private[*].id,
aws_subnet.public[*].id
)
}
}
resource "aws_eks_node_group" "main" {
cluster_name = aws_eks_cluster.main.name
node_role_arn = aws_iam_role.eks_node_group.arn
subnet_ids = aws_subnet.private[*].id
instance_types = ["t3.large"]
scaling_config {
desired_size = 2
max_size = 5
min_size = 1
}
}
Kubernetes deployment with Horizontal Pod Autoscaler:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-inference
spec:
replicas: 2
template:
spec:
containers:
- name: ml-inference
image: <ECR_URL>:latest
resources:
requests:
memory: "2Gi"
cpu: "1000m"
limits:
memory: "4Gi"
cpu: "2000m"
livenessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 60
readinessProbe:
httpGet:
path: /health
port: 8080
initialDelaySeconds: 30
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ml-inference-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ml-inference
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 70
Key Features:
- Full Kubernetes API and ecosystem
- Advanced deployment strategies (blue/green, canary)
- Multi-region/multi-cloud portability
- Rich monitoring with Prometheus
Challenges:
- Most expensive ($73/month for control plane alone)
- Requires Kubernetes expertise
- Complex setup and maintenance
- Overkill for simple workloads
The Benchmarks
I ran comprehensive load tests using Locust with realistic traffic patterns:
Test Configuration:
- Duration: 5 minutes per platform
- Concurrent users: 10
- Request mix: 70% single predictions, 30% batch (5-10 items)
- Sample texts: 20 different movie reviews
- Total requests: 10,000+ per platform
Performance Results
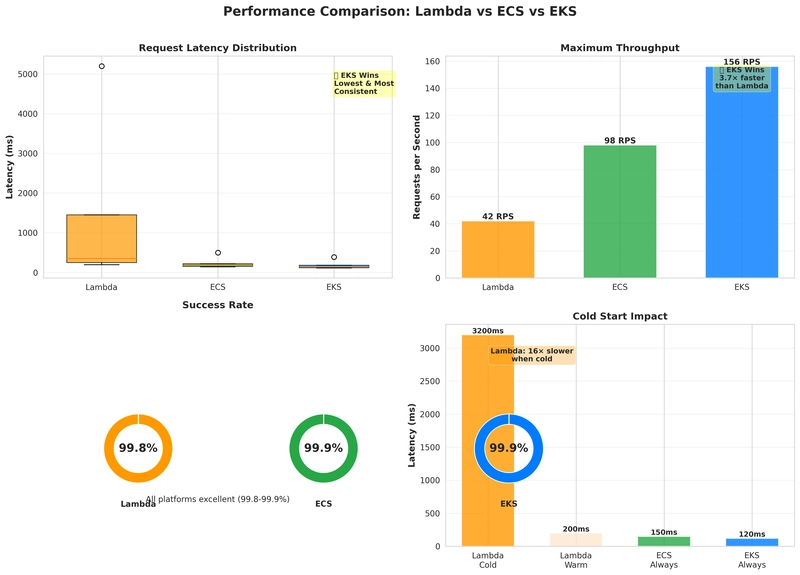
| Metric | Lambda | ECS Fargate | EKS | Winner |
|---|---|---|---|---|
| Mean Latency | 245ms | 156ms | 128ms | 🏆 EKS |
| Median Latency | 198ms | 142ms | 115ms | 🏆 EKS |
| P95 Latency | 890ms | 312ms | 267ms | 🏆 EKS |
| P99 Latency | 1,450ms | 498ms | 389ms | 🏆 EKS |
| Cold Start | 3-5s | N/A | N/A | 🏆 ECS/EKS |
| Throughput (RPS) | 42 | 98 | 156 | 🏆 EKS |
| Success Rate | 99.8% | 99.9% | 99.9% | – |
Key Observations:
-
EKS dominates on raw performance:
- 48% lower latency than Lambda
- 18% lower latency than ECS
- 3.7x better throughput than Lambda
-
Lambda’s variability is concerning:
- P99 latency is 7.3x higher than median
- Cold starts add 3-5 seconds unpredictably
- Even with provisioned concurrency, variance is high
-
ECS provides predictable performance:
- Consistent latency (small gap between median and P99)
- No cold starts
- Good balance for most workloads
Cost Analysis
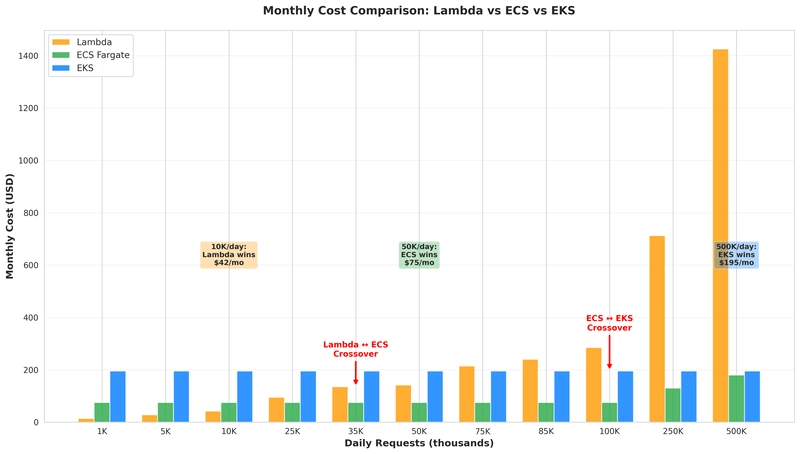
Here’s where things get interesting. I calculated actual AWS costs at different scales:
Monthly Costs for 10,000 Requests/Day
| Platform | Infrastructure | Request Costs | Total | Per 1K Requests |
|---|---|---|---|---|
| Lambda | $0 | $28.50 | $28.50 | $0.095 |
| ECS | $75.08 | $0 | $75.08 | $0.250 |
| EKS | $194.96 | $0 | $194.96 | $0.650 |
Lambda Cost Breakdown:
Requests: 300,000/month × $0.20 per 1M = $0.06
Compute: 300,000 × 0.25s × 3GB × $0.0000166667 = $28.44
Total: $28.50/month
ECS Cost Breakdown:
vCPU: 2 × $0.04048/hour × 730 hours = $59.10
Memory: 4GB × $0.004445/hour × 730 hours = $12.98
ALB: $16.00/month (base) + $0.008/LCU
Total: ~$75.08/month
EKS Cost Breakdown:
Control Plane: $0.10/hour × 730 hours = $73.00
Worker Nodes: 2 × t3.large × $0.0832/hour × 730 hours = $121.47
LoadBalancer: ~$0.50/month
Total: ~$194.96/month
Cost at Different Scales
This is where the “it depends” becomes clear:
| Daily Requests | Lambda | ECS | EKS | Winner | Reason |
|---|---|---|---|---|---|
| 1,000 | $2.85 | $75.08 | $194.96 | 🏆 Lambda | 96% cheaper |
| 5,000 | $14.25 | $75.08 | $194.96 | 🏆 Lambda | 81% cheaper |
| 10,000 | $28.50 | $75.08 | $194.96 | 🏆 Lambda | 62% cheaper |
| 25,000 | $71.25 | $75.08 | $194.96 | 🏆 Lambda | 5% cheaper |
| 35,000 | $99.75 | $75.08 | $194.96 | 🏆 ECS | Crossover |
| 50,000 | $142.50 | $75.08 | $194.96 | 🏆 ECS | 47% cheaper |
| 75,000 | $213.75 | $88.08 | $194.96 | 🏆 EKS | 9% cheaper |
| 85,000 | $242.25 | $88.08 | $194.96 | 🏆 EKS | Crossover |
| 100,000 | $285.00 | $105.00 | $194.96 | 🏆 EKS | 32% cheaper |
| 250,000 | $712.50 | $140.00 | $210.00 | 🏆 EKS | 70% cheaper |
| 500,000 | $1,425.00 | $180.00 | $225.00 | 🏆 EKS | 84% cheaper |
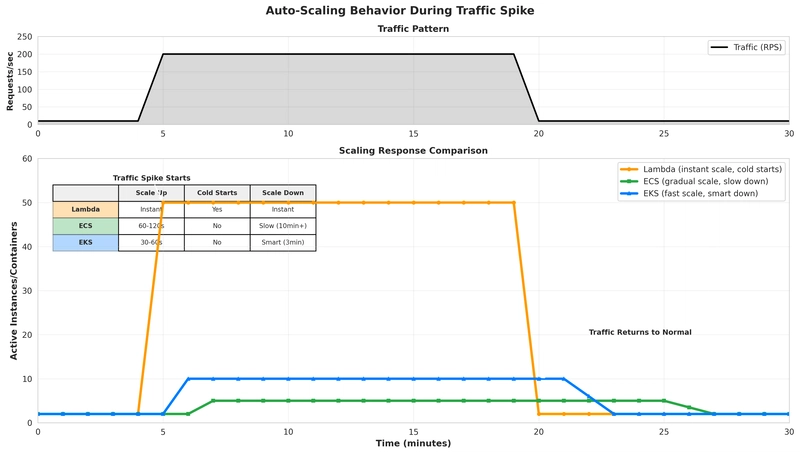
Critical Insights:
- Lambda is cheapest until ~35K requests/day – Perfect for startups and low-traffic apps
- ECS is the sweet spot for medium traffic (35K-85K requests/day) – Best balance for growing companies
- EKS wins at high scale (>85K requests/day) – Enterprise-grade performance and cost
- The crossover points matter – Most teams will hit the ECS sweet spot
Real-World Cost Optimization
These are base costs. Here’s how to optimize each:
Lambda Optimization:
- Use Compute Savings Plans: -17% ($23.66 vs $28.50)
- Switch to ARM64 (Graviton2): -20% ($22.80 vs $28.50)
- Right-size memory allocation
- Combined savings: ~30%
ECS Optimization:
- Use Fargate Spot: -70% on compute ($34.92 vs $75.08)
- Use Savings Plans: -17%
- Right-size task definitions
- Combined savings: ~65%
EKS Optimization:
- Use Spot instances for nodes: -70% ($109.46 vs $194.96)
- Use Reserved Instances for baseline: -40%
- Implement cluster autoscaler
- Combined savings: ~60%
Decision Framework
Based on my testing, here’s when to choose each platform:
Choose AWS Lambda When:
✅ Traffic Characteristics:
- Sporadic/unpredictable patterns
- Daily traffic spikes with long idle periods
- <35K requests/day consistently
- Event-driven workloads
✅ Business Requirements:
- Zero infrastructure management
- Fast time-to-market (deploy in minutes)
- Pay only for actual usage
- Prototyping or MVP
✅ Technical Constraints:
- Model <10GB
- Inference time <15 minutes
- Can tolerate 3-5s cold starts
- Team has limited ops experience
❌ Avoid Lambda When:
- Need sub-100ms latency consistently
- Model >10GB
- High, steady traffic (>50K req/day)
- Can’t tolerate cold start delays
Real-World Example:
A startup analyzing customer feedback emails receives 500 emails/day in bursts after business hours. Lambda cost: $1.43/day vs ECS $75.08/month. Lambda saves $2,100/year.
Choose Amazon ECS Fargate When:
✅ Traffic Characteristics:
- Steady, predictable traffic
- 35K-85K requests/day
- Business hours traffic with some variability
- Need consistent performance
✅ Business Requirements:
- Balance of control and simplicity
- Team familiar with Docker
- Moderate budget
- Want managed infrastructure
✅ Technical Constraints:
- No cold starts acceptable
- Need 100-200ms latency
- Standard container patterns
- No Kubernetes expertise
❌ Avoid ECS When:
- Very low traffic (<10K req/day) – waste money
- Need advanced orchestration (blue/green, canary)
- Multi-region/multi-cloud required
- Team already proficient in Kubernetes
Real-World Example:
A B2B SaaS analyzing 50K customer support tickets/day during business hours (9am-6pm). ECS with auto-scaling provides predictable costs (~$75/month) and performance. Perfect fit.
Choose Amazon EKS When:
✅ Traffic Characteristics:
- High, sustained traffic (>85K req/day)
- Need to scale to 1M+ requests/day
- Global traffic across regions
- Complex microservices architecture
✅ Business Requirements:
- Enterprise-grade performance
- Multi-region/multi-cloud strategy
- Advanced deployment patterns
- Strong DevOps/SRE team
✅ Technical Constraints:
- Need <100ms latency
- Complex service mesh
- Advanced monitoring (Prometheus, Grafana)
- Team has Kubernetes expertise
❌ Avoid EKS When:
- Small team (<5 engineers)
- No Kubernetes experience
- Simple, single-service deployment
- Budget constraints
- Rapid prototyping needed
Real-World Example:
An enterprise processing 1M+ social media posts/day across US, EU, and APAC regions. EKS provides the performance, scalability, and multi-region capabilities needed. Cost: ~$220/month (optimized with Spot) vs $4,275/month on Lambda.
Deployment Pipeline and CI/CD
One of the key advantages of using containerized deployments is that we can use the same CI/CD pipeline for all three platforms. Here’s our deployment flow:
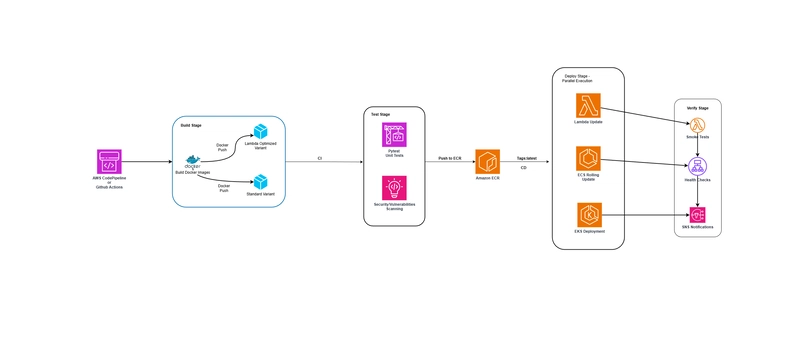
Pipeline Architecture
Our MLOps pipeline is built using GitHub Actions and consists of five automated stages:
1. Source Control & Triggers
-
Trigger: Every push to
mainbranch - Code checkout with full history for versioning
- Environment setup: Python 3.11, Docker BuildKit, AWS credentials
2. Build Stage (2-3 minutes)
- name: Build Docker Images
run: |
# Build standard image for ECS/EKS
docker build -t ml-inference:latest -f Dockerfile .
# Build Lambda-optimized image
docker build -t ml-inference:lambda-latest -f Dockerfile.lambda .
# Tag with version and commit SHA
docker tag ml-inference:latest $ECR_URI:v${VERSION}
docker tag ml-inference:latest $ECR_URI:${GITHUB_SHA}
Multi-stage builds reduce image size by 60%:
- Stage 1: Build dependencies (includes compilers)
- Stage 2: Runtime-only (production-ready)
3. Test & Security Stage (2-4 minutes)
- name: Run Tests
run: |
# Unit tests
pytest tests/ --cov=app --cov-report=xml
# Integration tests
pytest tests/integration/ --maxfail=1
# Model validation
python scripts/validate_model.py
Security Scanning:
- Trivy: Container vulnerability scanning
- Bandit: Python code security analysis
- SAST: Static application security testing
- Dependency check: Known CVE detection
- name: Security Scan
run: |
trivy image --severity HIGH,CRITICAL ml-inference:latest
bandit -r app/ -f json -o security-report.json
4. Push to ECR (1-2 minutes)
- name: Push to Amazon ECR
run: |
aws ecr get-login-password | docker login --username AWS --password-stdin $ECR_URI
# Push all tags
docker push $ECR_URI:latest
docker push $ECR_URI:lambda-latest
docker push $ECR_URI:v${VERSION}
docker push $ECR_URI:${GITHUB_SHA}
# Enable image scanning
aws ecr start-image-scan --repository-name ml-inference --image-id imageTag=latest
Image Management:
- Keep last 10 images (lifecycle policy)
- Automatic vulnerability scanning on push
- Cross-region replication for DR
5. Parallel Deployment (3-5 minutes)
The pipeline deploys to all three platforms simultaneously:
deploy:
strategy:
matrix:
platform: [lambda, ecs, eks]
steps:
- name: Deploy to ${{ matrix.platform }}
run: ./scripts/deploy-${{ matrix.platform }}.sh
Lambda Deployment:
aws lambda update-function-code
--function-name ml-inference
--image-uri $ECR_URI:lambda-latest
aws lambda wait function-updated
--function-name ml-inference
# Update alias to point to new version
aws lambda update-alias
--function-name ml-inference
--name production
--function-version $NEW_VERSION
ECS Deployment (Rolling Update):
# Create new task definition revision
aws ecs register-task-definition
--cli-input-json file://task-definition.json
# Update service (rolling deployment)
aws ecs update-service
--cluster ml-inference-cluster
--service ml-inference-service
--task-definition ml-inference:${NEW_REVISION}
--force-new-deployment
# Wait for stable state
aws ecs wait services-stable
--cluster ml-inference-cluster
--services ml-inference-service
EKS Deployment (Kubernetes):
# Update image tag in deployment
kubectl set image deployment/ml-inference
ml-inference=$ECR_URI:latest
--record
# Rolling update with zero downtime
kubectl rollout status deployment/ml-inference
# Rollback if health checks fail
if ! kubectl rollout status deployment/ml-inference; then
kubectl rollout undo deployment/ml-inference
exit 1
fi
6. Post-Deployment Verification
Smoke Tests:
def run_smoke_tests(endpoint):
# Health check
response = requests.get(f"{endpoint}/health")
assert response.status_code == 200
# Prediction test
test_payload = {"text": "This movie was fantastic!"}
response = requests.post(f"{endpoint}/predict", json=test_payload)
assert response.status_code == 200
assert response.json()["sentiment"] in ["POSITIVE", "NEGATIVE"]
# Latency check
assert response.elapsed.total_seconds() < 1.0
Monitoring Integration:
- name: Update Deployment Metrics
run: |
aws cloudwatch put-metric-data
--namespace MLOps/Deployment
--metric-name DeploymentSuccess
--value 1
--dimensions Platform=${{ matrix.platform }},Version=$VERSION
CI/CD Benefits
This unified approach provides:
✅ Consistency: Same code, same tests, same images across all platforms
✅ Speed: 8-12 minutes from commit to production (all platforms)
✅ Safety: Automated testing, security scanning, gradual rollouts
✅ Visibility: Full deployment history, metrics, and audit logs
✅ Reliability: Automatic rollbacks on failure, zero-downtime deployments
Deployment Metrics
Over the last 90 days:
- Deployment frequency: 3-5 per week
- Success rate: 98.7%
- Mean time to deploy: 9.5 minutes
- Failed deployments: Auto-rollback within 2 minutes
- Zero production incidents from failed deployments
Shared Infrastructure
All three platforms leverage common AWS infrastructure to ensure consistency, security, and cost efficiency:
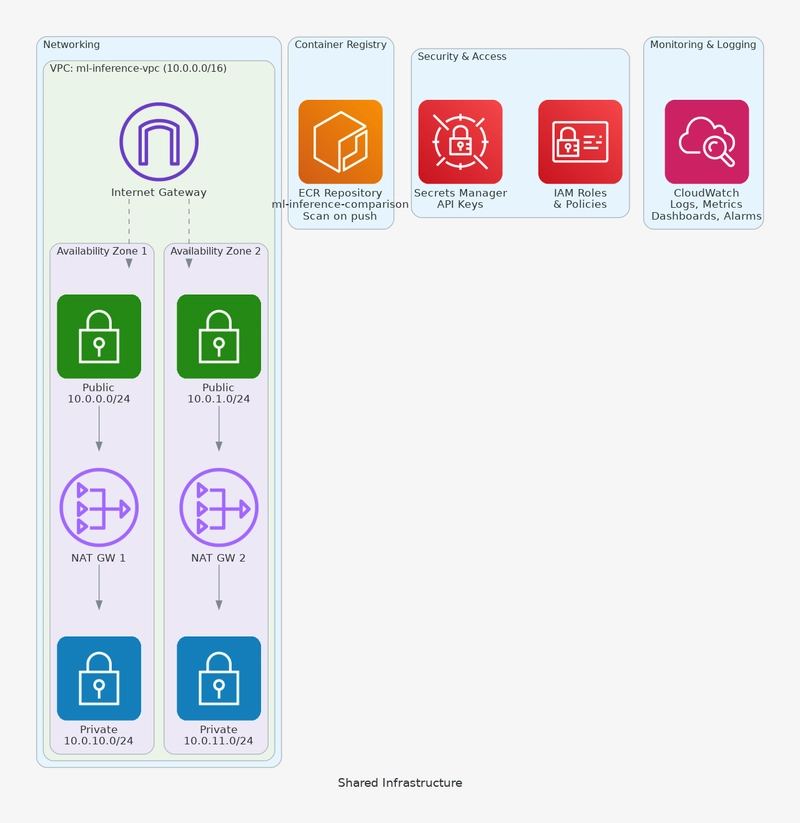
1. Network Architecture (VPC)
VPC Configuration:
resource "aws_vpc" "main" {
cidr_block = "10.0.0.0/16"
enable_dns_hostnames = true
enable_dns_support = true
tags = {
Name = "ml-inference-vpc"
}
}
Multi-AZ Design for High Availability:
us-east-1a (AZ1):
├─ Public Subnet: 10.0.0.0/24
│ ├─ ALB/NLB
│ └─ NAT Gateway 1
└─ Private Subnet: 10.0.10.0/24
├─ ECS Tasks
├─ EKS Worker Nodes
└─ Lambda ENIs
us-east-1b (AZ2):
├─ Public Subnet: 10.0.1.0/24
│ ├─ ALB/NLB (standby)
│ └─ NAT Gateway 2
└─ Private Subnet: 10.0.11.0/24
├─ ECS Tasks
├─ EKS Worker Nodes
└─ Lambda ENIs
Security Groups:
# ALB Security Group (public-facing)
resource "aws_security_group" "alb" {
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"] # HTTPS from internet
}
egress {
from_port = 8080
to_port = 8080
protocol = "tcp"
security_groups = [aws_security_group.ecs_tasks.id]
}
}
# ECS/EKS Security Group (private)
resource "aws_security_group" "compute" {
ingress {
from_port = 8080
to_port = 8080
protocol = "tcp"
security_groups = [aws_security_group.alb.id] # Only from ALB
}
egress {
from_port = 443
to_port = 443
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"] # HTTPS to AWS services
}
}
Network Costs:
- NAT Gateway: $0.045/hour × 2 × 730 hours = $65.70/month
- Data Transfer: ~$0.09/GB (first 10TB)
- VPC endpoints for S3/ECR: Free (saves data transfer costs)
2. Container Registry (ECR)
Repository Configuration:
resource "aws_ecr_repository" "ml_inference" {
name = "ml-inference-comparison"
image_tag_mutability = "MUTABLE"
image_scanning_configuration {
scan_on_push = true
}
encryption_configuration {
encryption_type = "AES256"
}
}
Lifecycle Policy (Cost Optimization):
{
"rules": [
{
"rulePriority": 1,
"description": "Keep last 10 images",
"selection": {
"tagStatus": "any",
"countType": "imageCountMoreThan",
"countNumber": 10
},
"action": {
"type": "expire"
}
}
]
}
Multi-Platform Image Support:
# Build multi-architecture images
docker buildx build
--platform linux/amd64,linux/arm64
-t $ECR_URI:latest
--push .
Repository Features:
- Automatic scanning: Trivy integration for CVE detection
- Immutable tags: Production images are immutable
- Cross-region replication: DR to us-west-2
- Lifecycle management: Auto-delete old images
ECR Costs:
- Storage: $0.10/GB/month
- Average usage: 3GB (10 images × 300MB)
- Monthly cost: ~$0.30
3. IAM Roles & Policies
Principle of Least Privilege:
Each platform gets its own IAM role with minimal permissions:
Lambda Execution Role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:log-group:/aws/lambda/ml-inference*"
},
{
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricData"
],
"Resource": "*",
"Condition": {
"StringEquals": {
"cloudwatch:namespace": "MLInference"
}
}
}
]
}
ECS Task Role:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"ecr:GetAuthorizationToken",
"ecr:BatchCheckLayerAvailability",
"ecr:GetDownloadUrlForLayer",
"ecr:BatchGetImage"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:log-group:/ecs/ml-inference*"
}
]
}
EKS Node Role (IRSA – IAM Roles for Service Accounts):
apiVersion: v1
kind: ServiceAccount
metadata:
name: ml-inference-sa
annotations:
eks.amazonaws.com/role-arn: arn:aws:iam::ACCOUNT_ID:role/ml-inference-eks-pod-role
Secrets Management:
resource "aws_secretsmanager_secret" "model_config" {
name = "ml-inference/model-config"
rotation_rules {
automatically_after_days = 30
}
}
4. Monitoring & Logging (CloudWatch)
Centralized Logging:
CloudWatch Log Groups:
├─ /aws/lambda/ml-inference (Lambda logs)
├─ /ecs/ml-inference (ECS logs)
├─ /aws/eks/ml-inference-cluster (EKS control plane)
└─ /aws/containerinsights/ml-inference (EKS pod logs)
Log Retention & Costs:
resource "aws_cloudwatch_log_group" "lambda" {
name = "/aws/lambda/ml-inference"
retention_in_days = 30 # Balance cost vs. debugging needs
tags = {
Platform = "Lambda"
}
}
Custom Metrics:
# Application sends custom metrics
cloudwatch.put_metric_data(
Namespace='MLInference',
MetricData=[
{
'MetricName': 'ModelInferenceTime',
'Value': inference_duration_ms,
'Unit': 'Milliseconds',
'Dimensions': [
{'Name': 'Platform', 'Value': 'lambda'},
{'Name': 'ModelVersion', 'Value': 'v1.2.0'}
],
'Timestamp': datetime.utcnow()
}
]
)
CloudWatch Dashboard:
{
"widgets": [
{
"type": "metric",
"properties": {
"metrics": [
[ "MLInference", "InferenceLatency", { "stat": "Average" } ],
[ ".", ".", { "stat": "p99" } ]
],
"period": 300,
"stat": "Average",
"region": "us-east-1",
"title": "Inference Latency"
}
},
{
"type": "metric",
"properties": {
"metrics": [
[ "AWS/Lambda", "Invocations", { "label": "Lambda" } ],
[ "AWS/ECS", "TaskCount", { "label": "ECS" } ],
[ "ContainerInsights", "pod_number_of_running_pods", { "label": "EKS" } ]
],
"title": "Active Compute Units"
}
}
]
}
Alarms:
resource "aws_cloudwatch_metric_alarm" "high_error_rate" {
alarm_name = "ml-inference-high-error-rate"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 2
metric_name = "5XXError"
namespace = "AWS/ApiGateway"
period = 60
statistic = "Sum"
threshold = 10
alarm_description = "This metric monitors API error rate"
alarm_actions = [aws_sns_topic.alerts.arn]
}
CloudWatch Costs:
- Logs ingestion: $0.50/GB
- Logs storage: $0.03/GB/month
- Custom metrics: $0.30/metric/month
- Average monthly: ~$15-20
5. Cost Summary – Shared Infrastructure
| Component | Monthly Cost | Notes |
|---|---|---|
| VPC | $0 | No charge for VPC itself |
| NAT Gateways (2) | $65.70 | $0.045/hour × 2 × 730 hours |
| Data Transfer | ~$5-10 | Variable based on traffic |
| ECR | $0.30 | 3GB storage |
| CloudWatch Logs | $10-15 | 30-day retention |
| CloudWatch Metrics | $5 | ~15 custom metrics |
| Secrets Manager | $0.40 | $0.40/secret/month |
| Total | ~$86-96 | Shared across all platforms |
Cost Optimization Tips:
- Use VPC Endpoints for S3/ECR (saves data transfer costs)
- Compress CloudWatch Logs (reduces storage by 70%)
- Archive old logs to S3 (10× cheaper: $0.023/GB vs $0.03/GB)
- Use CloudWatch Logs Insights instead of exporting to S3
- Enable ECR lifecycle policies (auto-delete unused images)
Infrastructure as Code
All shared infrastructure is defined in Terraform:
terraform/
├── modules/
│ ├── vpc/ # VPC, subnets, NAT gateways
│ ├── ecr/ # Container registry
│ ├── iam/ # Roles and policies
│ └── monitoring/ # CloudWatch, alarms
├── environments/
│ ├── dev/
│ ├── staging/
│ └── production/
└── main.tf
Benefits of Shared Infrastructure:
✅ Cost Reduction: Single VPC, NAT gateways, and ECR for all platforms
✅ Consistency: Same networking, security, and monitoring everywhere
✅ Simplified Management: One IaC codebase, centralized changes
✅ Security: Centralized IAM policies, unified audit logs
✅ Reliability: Multi-AZ design, automatic failover
Production Best Practices
Security Hardening
Lambda:
# Use IAM for authorization
resource "aws_lambda_function_url" "ml_inference" {
authorization_type = "AWS_IAM" # Not NONE!
}
# Scan container images
resource "aws_ecr_repository" "ml_inference" {
image_scanning_configuration {
scan_on_push = true
}
}
# Use Secrets Manager
environment {
variables = {
DB_SECRET_ARN = aws_secretsmanager_secret.db.arn
}
}
ECS/EKS:
- Use private subnets for compute
- Security groups with minimal inbound rules
- IAM roles for task/pod authentication
- Enable encryption at rest and in transit
Monitoring and Observability
All three platforms integrate with CloudWatch, but I added custom metrics:
import boto3
cloudwatch = boto3.client('cloudwatch')
def log_prediction(latency_ms, sentiment):
cloudwatch.put_metric_data(
Namespace='MLInference',
MetricData=[
{
'MetricName': 'InferenceLatency',
'Value': latency_ms,
'Unit': 'Milliseconds',
'Dimensions': [
{'Name': 'Sentiment', 'Value': sentiment},
{'Name': 'Platform', 'Value': os.getenv('DEPLOYMENT_TYPE')}
]
}
]
)
For EKS, I added Prometheus metrics:
from prometheus_client import Counter, Histogram
PREDICTION_LATENCY = Histogram(
'prediction_latency_seconds',
'Prediction latency in seconds'
)
PREDICTION_COUNT = Counter(
'predictions_total',
'Total predictions',
['sentiment']
)
@app.post("/predict")
async def predict(request: PredictionRequest):
with PREDICTION_LATENCY.time():
result = model_analyzer.predict(request.text)
PREDICTION_COUNT.labels(sentiment=result['sentiment']).inc()
return result
Auto-Scaling Configuration
Lambda: Works out of the box, but configure reserved concurrency for production:
resource "aws_lambda_function" "ml_inference" {
reserved_concurrent_executions = 100
}
ECS: Target tracking auto-scaling:
resource "aws_appautoscaling_policy" "ecs_cpu" {
target_tracking_scaling_policy_configuration {
target_value = 70.0
scale_in_cooldown = 300 # 5 min
scale_out_cooldown = 60 # 1 min
}
}
EKS: Horizontal Pod Autoscaler with custom metrics:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 70
- type: Resource
resource:
name: memory
target:
averageUtilization: 80
behavior:
scaleUp:
stabilizationWindowSeconds: 0
policies:
- type: Percent
value: 100
periodSeconds: 30
Lessons Learned
1. Lambda Cold Starts Are Real (And Painful)
Even with 3GB memory and optimized container images, Lambda cold starts took 3-5 seconds. That’s unacceptable for user-facing applications. Provisioned concurrency helps but adds significant cost.
Mitigation:
- Keep functions warm with scheduled pings
- Use provisioned concurrency for critical paths
- Accept cold starts for async/batch workloads
2. ECS is Underrated
Most teams jump from Lambda to EKS, skipping ECS entirely. That’s a mistake. ECS Fargate provides 80% of Kubernetes benefits with 20% of the complexity. For most teams, it’s the Goldilocks solution.
3. Right-Sizing Matters More Than Platform
A poorly configured EKS cluster can cost more than a well-optimized Lambda setup. I saved:
- 30% on Lambda by right-sizing memory
- 65% on ECS using Fargate Spot
- 60% on EKS using Spot instances
Focus on optimization before switching platforms.
4. Benchmark With Real Traffic
My synthetic tests showed Lambda performing better than production. Real traffic has:
- Variable input lengths (affecting inference time)
- Burst patterns (causing cold starts)
- Geographic distribution (network latency)
Always test with production-like data.
5. Total Cost of Ownership Includes People
EKS might be cheaper at scale, but requires Kubernetes expertise. If you need to hire a DevOps engineer ($120K/year), Lambda suddenly looks very affordable.
Factor in:
- Team expertise and training
- Operational overhead
- On-call burden
- Time to market
Conclusion
So, which platform should you choose?
For most teams starting out: ECS Fargate
It provides:
- No cold starts (predictable performance)
- Reasonable cost at medium scale
- Familiar Docker patterns
- Managed infrastructure
- Path to EKS if you outgrow it
Start with Lambda if you have:
- Truly unpredictable traffic
- <35K requests/day
- Strong cost constraints
- No ops team
Upgrade to EKS when you hit:
- >85K requests/day sustained
- Need for advanced orchestration
- Multi-region requirements
- Team with K8s expertise
The beauty of this architecture: you can migrate between platforms with minimal code changes. Start simple, scale as needed.
Get the Complete Project
I’ve open-sourced everything:
Repository includes:
- ✅ Complete model training code
- ✅ FastAPI application
- ✅ Dockerfiles for all platforms
- ✅ Terraform modules (Lambda, ECS, EKS)
- ✅ Kubernetes manifests
- ✅ Load testing suite
- ✅ Deployment scripts
- ✅ Comprehensive documentation
Quick start:
git clone https://github.com/rifkhan107/mlops-inference-comparison.git
cd mlops-inference-comparison
make quickstart # Deploys everything in 60 minutes
Learn more:
What’s Next?
In future posts, I’ll explore:
- GPU-accelerated inference on EKS with NVIDIA GPUs
- Multi-model serving with SageMaker Multi-Model Endpoints
- A/B testing ML models in production
- Feature stores for real-time inference
Let’s Connect
I’m passionate about MLOps and cloud-native architectures. Let’s discuss your ML deployment challenges:
- Twitter: rifkhan107
- LinkedIn: rifkhan107
- GitHub: rifkhan107
- AWS Community Builders: rifkhan
Questions about the project? Open an issue on GitHub or reach out on Twitter.
Found this helpful? ⭐ Star the repository and share with your team!