Day 16 of improving my Data Science skills
Over the weekend I started the Introduction to Statistics in Python course, what stood out for me is numerical summary statistics – Measure of center. They help us summarize our data but choosing the correct “average” that truly represents the data is very important, else we will be fooled by extreme values.
Data can lie to you if you use the wrong average.
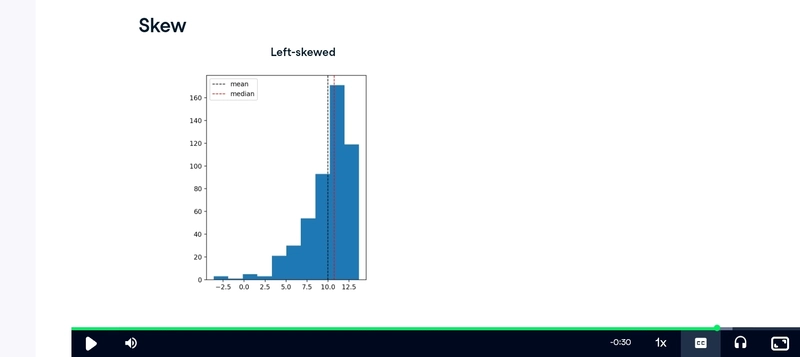
Both mean and median try to tell you what a “typical” value is, but they behave very differently when the data is uneven (skewed).
If you choose the wrong one:
You can misrepresent reality
Make bad business decisions
Or give misleading insights
Imagine 5 kids with these allowances: ₦100, ₦120, ₦110, ₦130, ₦1,000,000
Mean (average) = very large because of the one rich kid
Median (middle) = around ₦120, this represents most kids
So if you tell people “the average allowance is ₦200,000” using the mean, you would be lying without knowing it.
That’s why, mean is good when numbers are balanced and median is better when there are extreme values (outliers)
We use mean when the data is symmetrical (evenly spread) because:
No extreme values are pulling the average
Mean gives a fair center
We use median when the data is skewed (has very big or very small values) because:
A few extreme values can distort the mean
Median shows what is typical for most people
In Real life:
House prices are reported using median so one mansion doesn’t fake the market.
Recruiters use median salary, not mean, so one billionaire doesn’t distort pay expectations.
Returns are often skewed, so analysts rely heavily on the median.
Learning this over again, made me understand the topic more clearly.
This indeed is the beauty of Statistics 😊(my professor would correct me and say “Mathematics” but let me cook 😅)
Even on days when learning feels heavy, I’m grateful for every concept I now understand better than yesterday.
On to the next lesson
-SP 🤍