Day 1 – Setting up the Scanner
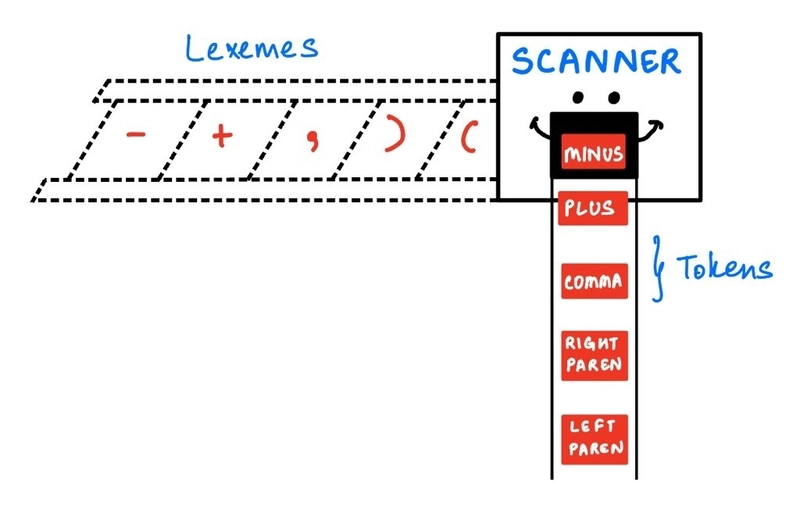
Today, I created the Lox, Scanner, Token, and TokenType classes. The Scanner’s job is to parse through the code and generate tokens out of it. Tokens are essentially the smallest meaningful units of a programming language, and can include keywords, identifiers, and literals.
Ex: this is a token used to refer to the current object in a Java class.
What I built: Commit b071ffb
What I understood:
- The Lox class takes in the file/prompt given by the user.
- It then creates a scanner object using the run() function, that reads each lexeme (raw unit of code) and tries to map it to a type, after which a list of (meaningful) tokens is created.
- Also, error handling is separated from the Scanner class to keep the latter’s work as simple as possible.
- Error handling is kept minimal here: line, column, message
- The Token class has a method that returns the type, lexeme, and literal
- TokenType is an enum in which the types are mentioned for the lexeme to be matched to, during comparison.
- Scanner creates an array of tokens, which are lexemes mapped to their TokenType.
- An offset counter is maintained to track the position of the scanner w.r.t. a lexeme.
- Switch-case is written to find lexemes’ types, after which the token is added to the array.
- For now, this only deals with single-character lexemes and comparison operators.
private void scanToken() {
char c = advance();
switch(c) {
case '(': addToken(LEFT_PAREN); break;
case ')': addToken(RIGHT_PAREN); break;
case '{': addToken(LEFT_BRACE); break;
case '}': addToken(RIGHT_BRACE); break;
// ...
case '!':
addToken(match('=') ? BANG_EQUAL : BANG); break;
case '=':
addToken(match('=') ? EQUAL_EQUAL : EQUAL); break;
// ...
default:
Lox.error(line, "Unexpected character!");
break;
}
}
What’s next:
- Scanning longer lexemes, keywords, and literals.
Musings:
Tokens are the building blocks of code, like cells are for life, or atoms for matter. We never really get to see them at work, but knowing that something magnificent and efficient is but only an aggregation of countless tiny parts working together, is both very humbling and empowering. When we see machines work so well, we know so little of all the work that goes behind it. Building this interpreter is a nice reminder for me to acknowledge all the effort everyone puts in.