Dark Web Scraping Using AI : Tools, Techniques, and Challenges
The Dark Web has a lot of useful information, especially in hidden forums and marketplaces. But getting to that data isn’t always easy. You’ll often run into things like CAPTCHAs and tools that block web scraping. And writing your own code to get past these issues can take a lot of time and effort.
In this blog, i’ll show you an easier way. Using Llama, we can collect, understand, and even talk about Dark Web data without writing hundreds of lines of code or getting stuck on common problems.
Can you believe it? Amazing, right? Let’s dive in!
As always, our go-to tool for building powerful applications is Python🐍!
To get started, let’s explore the necessary requirements and dependencies .
#requirements.txt
streamlit
langchain
langchain_ollama
selenium
beautifulsoup4
Streamlit allows for quick creation of interactive web apps, LangChain offers a framework for building workflows with language models for tasks like Q&A and summarization, with LangChain_Ollama enabling integration with Ollama models , while Selenium automates browser actions for testing and scraping dynamic pages, and BeautifulSoup4 parses data from HTML and XML.
I recommend creating a Python Virtual Environment to keep all our project requirements organized, and here’s how
python3 -m venv <venv_name>
Then activate it using
<venv_name>Scriptsactivate
Now, let’s create a file called requirements.txt, and Install all the requirements with:
pip3 install -r requirements.txt
With everything ready, we’ll create our main Python file to build the app’s interface, so we’ll use Streamlit:
#main.py
import streamlit as st
st.title ("zerOiQ Scraper")
url = st.text_input("Search For Website")
And we could add something unique, like a banner, for example
st.markdown(
"""
```
_________________/\\___________________/\_________________
_______________/\///\______________/\\/\\______________
_____________/\/__///\___/\___/\//////\____________
____________/\______//\_///___/\______//\___________
___________/\_______/\__/\_//\______/\____________
___________//\______/\__/\__///\\/\\/_____________
____________///\__/\____/\____////\//_______________
______________///\\/_____/\_______///\\\____________
________________/////_______///__________//////_____________
```
""",
unsafe_allow_html=True
)
and the result should be after running
streamlit main.py --server.port <Port>
Now, let’s move ahead and build our scraping function.
#scrape.py
import selenium.webdriver as webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.firefox.options import Options
def scrapWebsite(website):
options = Options()
#headless Browsing
options.add_argument("--headless")
# Path to the firefox WebDriver and Profile
options.profile = r" FireFox Profile "
firefoxDriver_path = "./geckodriver.exe"
service = Service(firefoxDriver_path)
driver = webdriver.Firefox(service=service, options=options)
try:
driver.get(website)
print("page loaded ..")
html = driver.page_source
return html
except Exception as e:
print(f"An error occurred: {str(e)}")
To retrieve your Firefox profile path, simply open Firefox, type about:profiles in the address bar, and just find the one you’re using, and copy the Root Directory path .
In summary, this code aims to load a website in headless Firefox and retrieve the HTML Source Code .
Got it! Now that we have the website loaded, let’s create a function to extract data from it using BeautifulSoup.
#scrape.py
..
def extract_body_content(html_content):
soup = BeautifulSoup(html_content, "html.parser")
body_content = soup.body
if body_content:
return str(body_content)
return "Nothing"
The extract_body_content function extracts the main content within the <body> tag from an HTML page.
It takes html_content as input, uses BeautifulSoupto parse it, and then finds the <body> tag . If the <body> tag exists, it returns its content as a string; if not, it returns “Nothing”.
This function is useful for isolating the primary content of a webpage .
After extracting the data, we need to clean it up and retain only the relevant information.
#scrape.py
..
def clean_body_content(body_content):
soup = BeautifulSoup(body_content, "html.parser")
for script_or_style in soup(["script", "style"]):
script_or_style.extract()
cleaned_content = soup.get_text(separator="n")
cleaned_content = "n".join(
line.strip() for line in cleaned_content.splitlines() if line.strip()
)
return cleaned_content
The clean_body_content function is designed to filter out unnecessary elements and keep only relevant text from the HTML body content.
First, it takes body_content as input and parses it with BeautifulSoup. It removes all <script> and <style> tags to eliminate JavaScript and CSS content, which aren’t typically relevant.
Then, it retrieves the remaining text and formats it by stripping out extra whitespace. It does this by splitting the text into lines, removing empty lines, and joining the cleaned lines with line breaks and , readable text.
And The split_dom_content() function breaks down a large HTML or text content dom_content into smaller, manageable chunks, each with a maximum length specified by max_length .
#scrape.py
..
def split_dom_content(dom_content, max_length=6000):
return [
dom_content[i : i + max_length] for i in range(0, len(dom_content), max_length)
]
It does this by iterating over dom_contentin increments of max_length, creating a list where each element is a slice of dom_contentno longer than max_length.
This function is especially useful for handling long text data in parts, such as when processing or analyzing content in limited-size segments.
Now let’s integrate the functions we created into the main function and call them in sequence to process the webpage content.
#main.py
..
from Scrape import (
scrapWebsite ,
split_dom_content ,
clean_body_content ,
extract_body_content
)
st.title ("AI Scraper")
url = st.text_input("Search For Website")
if st.button("Start Scraping"):
if url :
st.write("Scraping...")
result = scrapWebsite(url)
# print(result)
bodyContent = extract_body_content(result)
cleanedContent = clean_body_content(bodyContent)
st.session_state.dom_content = cleanedContent
with st.expander ("View All Content") :
st.text_area("Content" , cleanedContent, height=300)
By creating a simple Streamlit interface to scrape and display webpage content, the user enters a URL in a text input field st.text_input .
When the “Start Scraping” button is clicked, it checks if the URL field has content , if so, it initiates the scraping process by calling scrapWebsite(url), which retrieves the raw HTML. The extract_body_contentfunction then isolates the main
content, and clean_body_content filters out unnecessary elements, like scripts and styles.
The cleaned content is stored in st.session_state.dom_content for session persistence. Lastly, a text area displays the cleaned content, allowing the user to view the extracted text.
Until now, we’ve done a great job creating the web scraper and extracting all data from our target website.
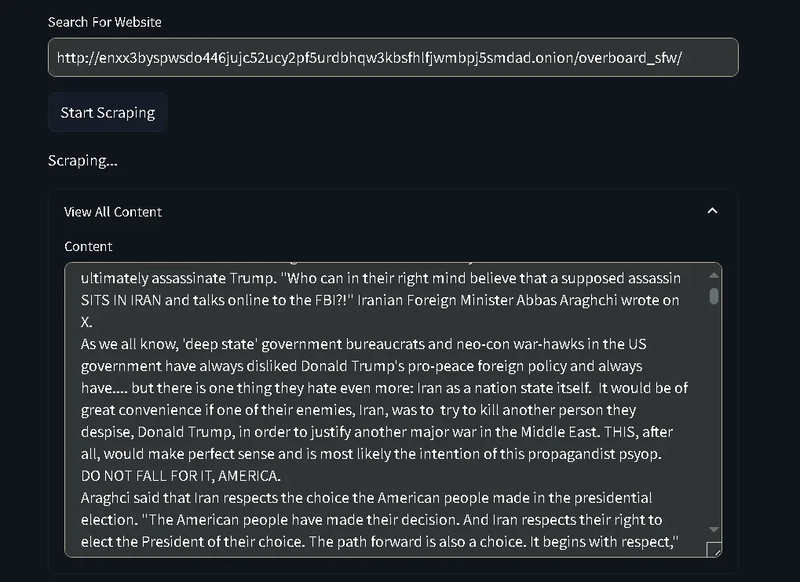
We’ve successfully built our web scraper, extracted the main content from our target website, and even cleaned up the data to focus on relevant information. We now have a tool that can dynamically retrieve and organize webpage content with just a few clicks.
We are now moving on to integrating Llama for content analysis.
#main.py
..
if "dom_content" in st.session_state:
parse_description = st.text_area("Describe what's in Your Mind ..'")
if st.button("Parse Content"):
if parse_description:
st.write("Parsing the content...")
# Parse the content with Ollama
dom_chunks = split_dom_content(st.session_state.dom_content)
First, we check if dom_contentis available in st.session_state, indicating that we have scraped data ready for processing. Then, we display a text area for the user to input a description of what they want to analyze.
When the Parse Content button is clicked, we ensure that the user has entered a description and proceed to parse the content.
We split the scraped data into smaller chunks using split_dom_contentto make it easier for Llama to handle.
This integration will allow us to interactively analyze and interpret the scraped content.
To integrate Llama into our code, we can create a new Python file called Ollama.py for example and import the necessary libraries to connect to and interact with Llama .
#Ollama.py
from langchain_ollama import OllamaLLM
from langchain_core.prompts import ChatPromptTemplate
OllamaLLMallows connecting and interacting with the Ollama language model for tasks like text processing and analysis , andChatPromptTemplate helps create templates for structured chat based prompts to send to the language model.
#Ollama.py
..
model = OllamaLLM(model="llama3")
It creates an instance of the OllamaLLM class, which connects to the llama3 model.
and then we need to import this template :
#Ollama.py
..
template = (
"You are tasked with extracting specific information from the following text content: {dom_content}. "
"Please follow these instructions carefully: nn"
"1. **Extract Information:** Only extract the information that directly matches the provided description: {parseDescription}. "
"2. **No Extra Content:** Do not include any additional text, comments, or explanations in your response. "
"3. **Empty Response:** If no information matches the description, return an empty string ('')."
"4. **Direct Data Only:** Your output should contain only the data that is explicitly requested, with no other text."
)
By creating a template with clear instructions for the Ollama model, it tells the model to extract specific information from the dom_content based on the parseDescription.
The model is instructed to only return the information that matches the description, avoid adding extra details, return an empty string if nothing matches, and provide only the requested data.
This ensures the extraction is focused and accurate.
#Ollama.py
..
def parseUsingOllama (domChunks , parseDescription) :
prompt = ChatPromptTemplate.from_template(template)
chain = prompt | model
finalResult = []
for counter , chunk in enumerate (domChunks , start=1) :
result = chain.invoke(
{"dom_content": chunk , "parseDescription": parseDescription}
)
print(f"Parsed Batch {counter} of {len(domChunks)}")
finalResult.append(result)
return "n".join(finalResult)
The parseUsingOllama function takes two inputs: domChunks (which are parts of the content) and parseDescription (which tells what information to extract). It creates a prompt with instructions for the model and then processes each chunk of content one by one.
For each chunk, the function asks the model to extract the relevant information based on the description.
It stores the results and shows which chunk is being processed. Finally, it returns all the results combined into one string.
This function makes it easier to extract specific details from large content by breaking it down into smaller parts.
To use the Llama model, we’ll need to install it from the official Ollama WEBSITE , and here’s a helpful GUIDE to assist you with the installation and running process [https://www.youtube.com/watch?v=PuJMmzGYZcY].
If you encounter any issues, check out the GitHub repository for additional useful commands and detailed instructions [https://github.com/ollama/ollama].
To integrate the Ollama parsing function back into our main application, we need to import the parseUsingOllamafunction from the parseOllama file.
#main.py
..
from parseOllama import parseUsingOllama
Once imported, we can call the parseUsingOllama function within our main function to process the content with the provided description
#main.py
..
parsed_result = parseUsingOllama(dom_chunks, parse_description)
st.write(parsed_result)
Now, the only thing left is to run our program and see it in action!
If everything looks good, we’ll know our program is ready and working as planned !
In summary, we created a streamlined web scraper that retrieves, cleans, and displays relevant content from a target website. We then integrated Llama via the Ollama API to help us analyze and extract specific information from the scraped data using a custom template. By breaking the content into manageable chunks and applying clear instructions, we ensure that only the most relevant data is displayed based on the user’s input .
This approach makes the data extraction process efficient, accurate, and user-friendly, and provides a solid foundation for further analysis and interaction with scraped web content .


