Context engineering for production-grade web agents
Web agents suffer from the AI demo-production gap.
Calvin French-Owen’s great post about AI products describes the demo-production gap:
In a strange twist, most AI demos nail the “upside” phase, but that’s where they get stuck: just a demo, not a product…
My belief is that [tools like Copilot, Cursor, Midjourney, etc.] can cross the chasm primarily because they aren’t flakey.
The upside of a web agent is great: it can automate web workflows that are tedious for humans to do.
But the downside of a flaky web agent is obvious: it can’t be used reliably in production! When we first tried to productionize our web agents, we had a <10% success rate for completing critical, repeatable tasks like downloading 50+ checks from a webpage.
We initially thought this high failure rate was due to prompt underspecification. If we learned to describe the ideal workflow precisely, we hoped the agent would somehow become reliable.
We’ve now come to believe that the main blocker for web agent reliability isn’t prompt engineering, but context engineering2. You can find a great primer on context engineering here. Tobi Lutke defines context engineering as “the art of providing all the context for the task to be plausibly solvable by the LLM.”, which spans far beyond the prompt given by the user.
With proper context engineering, we’ve gotten web agents to run for 60+ minutes without fail, processing checks and uploading them to a user’s S3/database through tool calls.
Here’s a video of our agents downloading checks over a 2.5 hour period on an anonymized recreation of a real customer portal.
This blog aims to explain why context engineering is especially important for web agents, and how we’ve successfully context engineered ours.
Understanding web agent context
Before we can explain why context engineering is important, we need to understand what web agent context is and the current web agent context paradigm.
Context refers to all the information an agent receives as input when determining the next step to take. This is more than just what the user provides in the task prompt.
For web agents, context also includes:
Web page content: a text representation of the web page so the agent can reason about the page
Agent memory: results from previous steps so the agent can see what it’s tried before
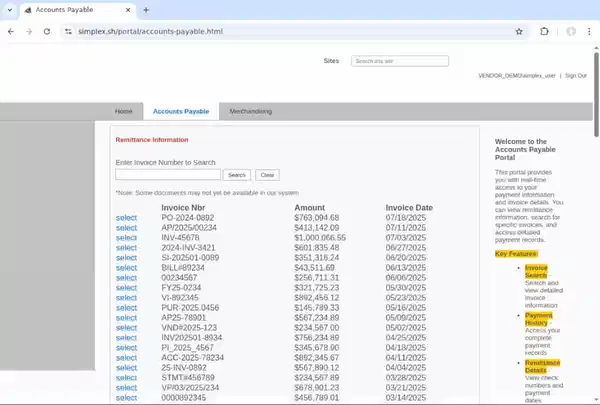
Let’s walk through a simple workflow where we login to a user portal, showing the actions taken and the context at each step.
At step 0, the web agent context comprises of the user-defined task “Login to the user portal” and what it currently sees on the web page. At this step, the agent plans then takes an action: click into the username field.
As the agent progresses through the remaining steps, it accumulates agent memory for the actions taken in previous steps. It also receives new web page content at every step. This is because actions can modify the web page state — at step 2, for example, the new web page content in the context informs the agent that we’ve successfully typed in the username from the previous step.
At the final step (step 3), we see the agent has successfully completed the user-defined task and accumulated the 3 previous steps of agent memory.
To reiterate, the context is made up of:
- User-defined task: the task the user wants the agent to complete
- Web page content: a text representation of the web page so the agent can reason about the page
- Agent memory: results from previous steps so the agent can see what it’s tried before
Problems with this architecture
There are two distinct problems with this architecture:
- The agent memory accumulates over time, which can lead to context confusion for longer workflows.
- The web page content changes at every step, and some web pages are content-dense, leading to the web page content dominating the context.
We’ll cover both these problems in depth below, then offer a solution to them.
Agent memory accumulation
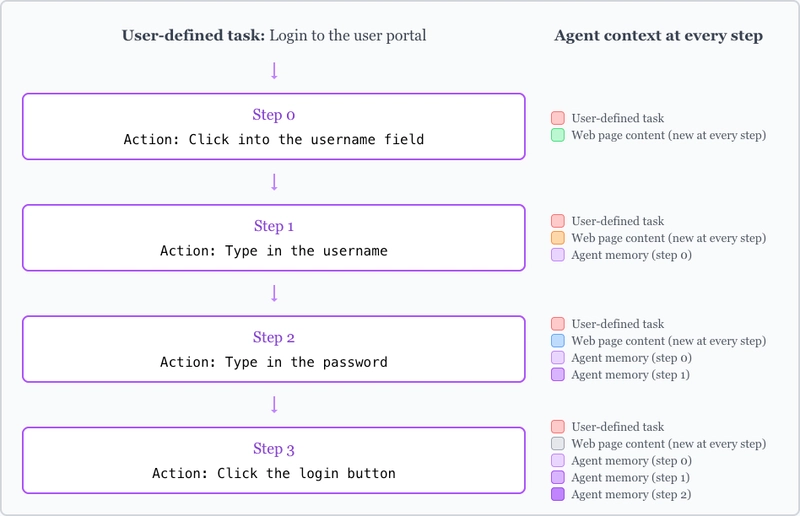
As the agent progresses through the workflow, the agent memory begins to accumulate. You can see this in the graph below (we’ve hidden the web content tokens for clarity):
The agent memory grows linearly with the number of steps. This makes sense, as we’re adding 1 step of action history at each step.
Unfortunately, this can cause longer workflows to suffer from context confusion, which is when “superfluous content in the context is used by the model to generate a low-quality response”3.
We’ve seen web page error modals from earlier steps be carried in the context and given attention to later on in the workflow, leading to the agent falsely thinking the webpage was broken when it wasn’t.
Web page content domination
Recall that the web page content changes after every step. Some web pages can add up to 30,000 (!) tokens to the context depending on how dense the page is — if it has dropdowns with hundreds of options or a table with thousands of rows, for example. That means we can have a step’s context that looks like this:
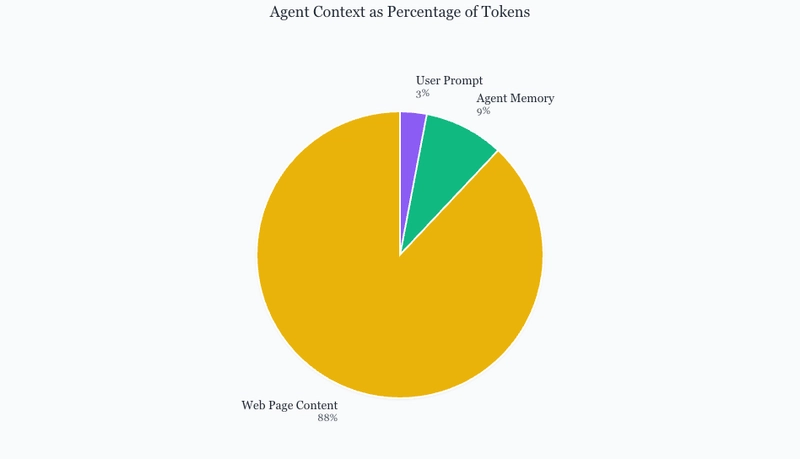
Here, the web page completely dominates 88% of the context, dwarfing the user-defined task and key information in the agent memory. This makes it far more difficult for the agent to parse the relevant information for its current step, often leading to agent confusion for more complex workflows.
We’ve illustrated two key factors that are increasing the context size:
- The agent memory accumulates with past actions and action results over many steps.
- The web page changes at every step which can vary in size and dominate the context.
To fix this, we need a way to prevent agent memory accumulation over time and prevent the web page content from confusing the agent’s ability to reason about its long-term goal.
Multi-agents for context compression
To solve these two problems, we can take inspiration from Anthropic’s multi-agent research system. Their research agents face similar challenges to our web agents.
In a single-agent system, conducting research from internet sources results in large-growing context that makes it difficult to reason about the long-term goal of putting together a cohesive report. As the agent continuously researches new topics, the context accumulates over time, meaning the agent might search for the same topic multiple times or lose relevant information in its vast context.
You can see their system architecture in a diagram from their blog post:
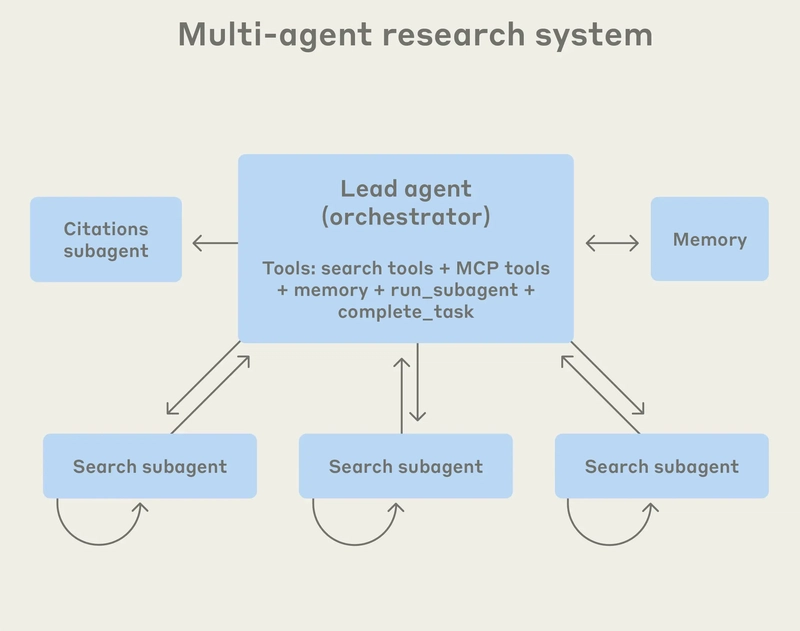
Instead of having a single agent handle both the searching and writing of the final report, Anthropic has a lead agent reason about the long-term goal and spawn sub-agents to do the actual searching.
For example, if the lead agent has the long standing task “search the latest trends in AI”, it might spawn search sub-agents to compile research on scoped sub-topics like “AI in healthcare and drug discovery”, “advances in computer vision and robotics”, and “AI regulation and ethics”.
Critically, these search sub-agents fill their context with a lot of information about their assigned sub-topic, but only pass compressed, key information back to the lead agent.
We’ll use the same core principle, with a lead orchestrator agent that reasons about the long-term goal and spawns web sub-agents to interact with the browser for scoped tasks.
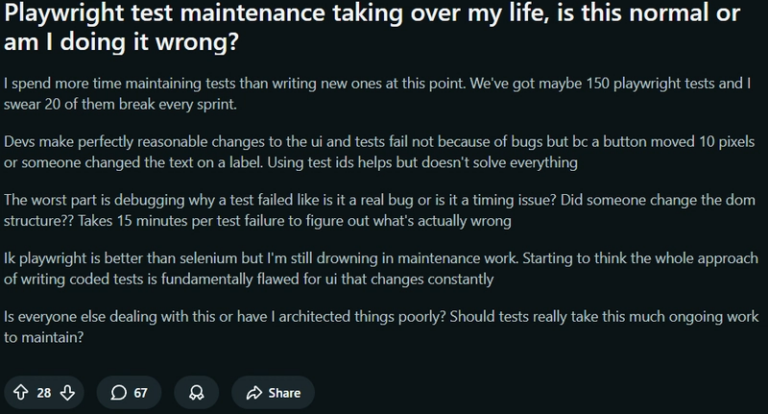
Let’s take a look at the workflow introduced at the beginning of this post: downloading checks from a user portal and uploading them to S3, tagged by invoice number and check number. In this flow, the agent must first click an invoice number from the invoice list which then opens a list of checks. The agent must then click into each check number in the list which downloads the check for that invoice.
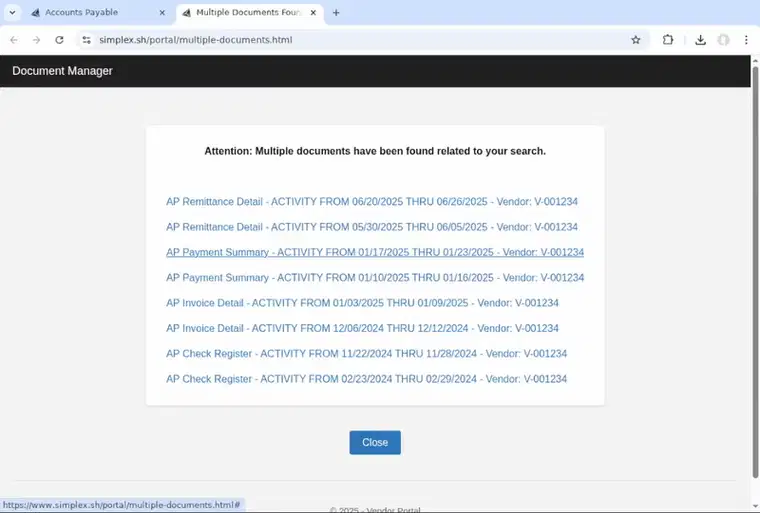
There’s a lot to keep track of here — an agent needs to know which checks it’s already downloaded, what the current check and invoice number is, which check from its download history to upload to S3, and when to switch between the inner check view and the outer invoice list.
We can split these tasks into sub-agents that will be called by the lead agent. One sub-agent might extract the list of invoices to process, perform the task of downloading a list of checks within an invoice, or navigate between the inner check view and the outer invoice list.
Our web multi-agent system now looks like this:
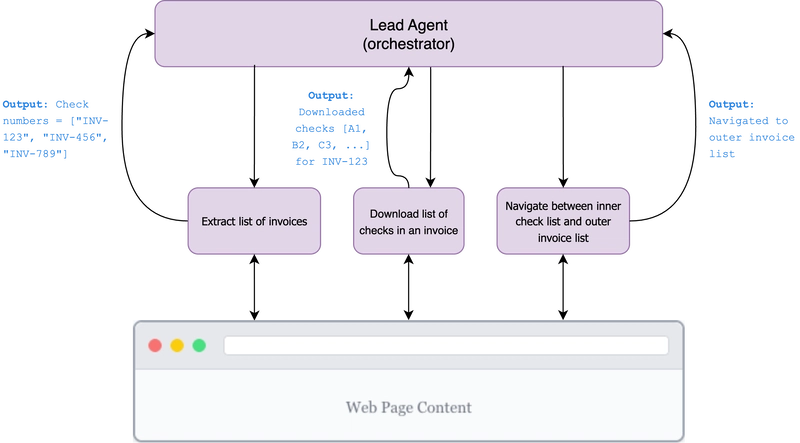
In this new architecture, the lead agent spawns sub-agents in sequence. First, it spawns the “Extract List of Invoices” sub-agent to extract the list of invoices to process. This sub-agent accumulates context and interacts with the browser only to extract the list of invoices to process. When it’s successfully extracted them from the page, it passes back only the invoice list back to the lead agent.
Then, the lead agent kills the “Extract List of Invoices” sub-agent and spawns a new sub-agent to download the list of checks within an invoice. After all the checks are downloaded, this sub-agent passes back the list of checks its downloaded to the lead agent.
A similar process happens for the third sub-agent in the diagram, the navigation sub-agent.
Over time, the lead agent still accumulates a small amount of memory as it needs to keep track of the information passed back from the sub-agents. You can see the context token accumulation for the lead agent is significantly lower with sub-agents in the graph below:
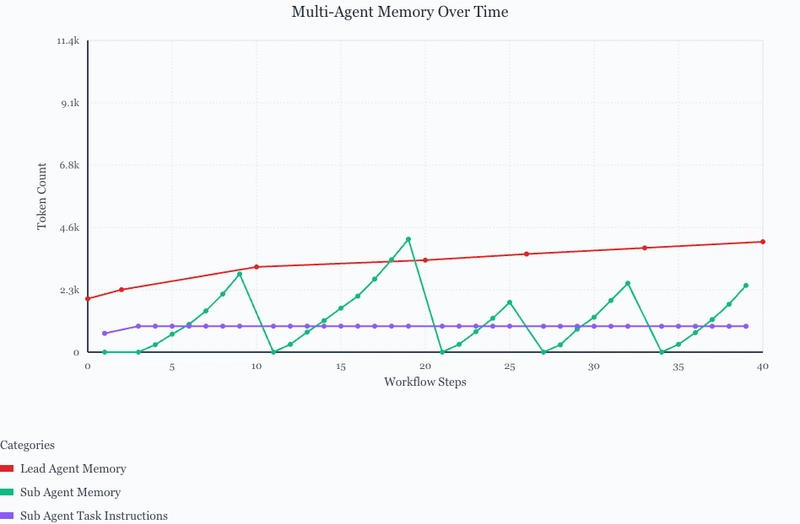
This leads to a web agent system that can run for hours without failure. With our single agent system, we were only able to download 5-10 invoices before the agent reached a failure state where it downloaded the same invoice multiple times, got confused with pagination or scroll controls, or downloaded the wrong file for a given invoice number.
With the multi-agent system, we’re able to download 50+ invoices, upload them to S3, and extract the correct check/invoice numbers across multiple tables, tabs, and pages without issue.
We’ve now solved both context problems with our multi-agent system by:
-
Offloading high reasoning tasks to a task manager that neither sees the large web page content nor accumulates agent memory. Instead, it only receives a summary of key information from the sub-agents it manages.
-
Scoping down long horizon tasks into smaller sub tasks to reduce agent memory accumulation in the sub-agents.
This is only the beginning
The techniques described in this article got us 70% of the way there for reliability. There’s a long tail of browser infrastructure, prompt engineering, agent evals, and more that is necessary to get customers fully into production.
We’ll talk about more of these learnings in future blog posts.
Get in touch
Simplex is the enterprise-grade web agent platform. We work directly alongside customers to integrate our web agents and web agent infrastructure into their existing systems, bringing tooling that enables web agents to run fully into production — far beyond simple prompt engineering.
We’re lucky enough be building Simplex with deeply supportive early customers and are ready to onboard more. If being able to perform complex web tasks consistently would be significantly revenue-generating for you, please book some time on our calendar here.