Building Stateful vs. Stateless AI Agents: A Deep Dive with Gaia Nodes and Supermemory
In the world of Large Language Models (LLMs), amnesia is the default. When you interact with an API, it knows nothing about you, your past projects, or the specific “truths” of your world.
While Retrieval-Augmented Generation (RAG) is the standard solution, implementing it effectively involves more than just database lookups. It requires managing Knowledge Conflict – the battle between what the model was trained on and what you want it to believe.
In this article, I will share a Streamlit-based project that puts a Decentralized Gaia Node (Stateless) in the ring against a Supermemory-Augmented Agent (Stateful). We will explore the code, the architecture, and the fascinating technical challenges of forcing an AI to accept “Blue Pineapples” as reality.
The Stack
We are combining decentralized inference with managed memory:
- Gaia Node: A decentralized, OpenAI-compatible LLM endpoint (running Mistral/Llama).
- Supermemory.ai: A managed vector database designed for building “Second Brains” for AI.
- Streamlit: For the split-screen comparison UI.
- OpenAI SDK: The connector for both the Gaia Node and the logic flow.
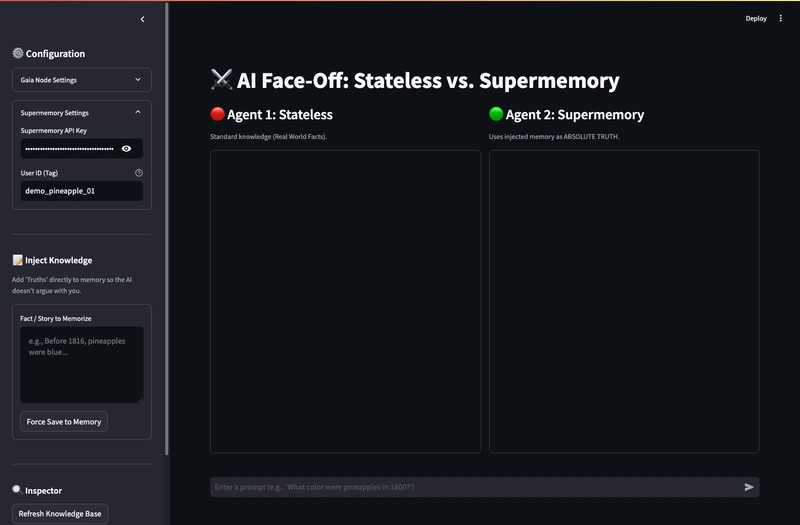
The Architecture
The application runs two parallel agents:
-
Agent 1 (Stateless): Direct Inference.
User Prompt->Gaia Node->Response. -
Agent 2 (Memory-Augmented):
-
User Prompt->Supermemory Search. -
Retrieval->System Prompt Injection. -
Augmented Prompt->Gaia Node. -
Response->User.
-
The Code
Since this project is self-contained, you don’t need a repository. You only need one Python file.
Prerequisites
pip install streamlit openai supermemory python-dotenv
The Logic (app.py)
This is the complete source code. It handles the API connections, the vector search, and the critical “Context Extraction” logic.
import streamlit as st
from openai import OpenAI
from supermemory import Supermemory
import os
import json
# --- Page Config ---
st.set_page_config(page_title="Memory vs Stateless Comparison", layout="wide")
# --- Custom CSS ---
st.markdown("""
<style>
.reportview-container .main .block-container {max-width: 95%;}
div[data-testid="stToast"] {
padding: 10px !important;
width: 300px !important;
}
</style>
""", unsafe_allow_html=True)
st.title("⚔️ AI Face-Off: Stateless vs. Supermemory")
def item_to_dict(item):
if isinstance(item, dict): return item
if hasattr(item, "model_dump"): return item.model_dump()
if hasattr(item, "dict"): return item.dict()
if hasattr(item, "json") and callable(item.json):
try: return json.loads(item.json())
except: pass
if hasattr(item, "__dict__"): return item.__dict__
return {"raw_string": str(item)}
def extract_text_from_item(item):
"""
Robust extraction that handles the 'chunks' structure seen in your logs.
"""
d = item_to_dict(item)
# 1. Check for 'chunks' (The structure in your screenshot)
if 'chunks' in d and isinstance(d['chunks'], list) and len(d['chunks']) > 0:
chunk = d['chunks'][0]
if isinstance(chunk, dict) and 'content' in chunk:
return chunk['content']
# 2. Check standard fields
candidates = [
d.get('content'), d.get('text'), d.get('document'),
d.get('page_content'), d.get('payload', {}).get('content'),
d.get('metadata', {}).get('content')
]
for c in candidates:
if c and isinstance(c, str) and len(c.strip()) > 0:
return c
return str(d)
def get_client(base_url, api_key):
clean_url = base_url.replace("/chat/completions", "")
return OpenAI(base_url=clean_url, api_key=api_key)
def query_supermemory(query, api_key, user_id):
if not api_key: return None
try:
os.environ["SUPERMEMORY_API_KEY"] = api_key
sm = Supermemory()
try:
data = sm.search.execute(q=query, container_tags=[user_id], limit=3)
except TypeError:
data = sm.search.execute(q=query, limit=3)
if data and hasattr(data, 'results') and len(data.results) > 0:
return data.results
except Exception as e:
print(f"Search Error: {e}")
return None
def save_to_supermemory_raw(content, api_key, user_id):
"""Directly saves raw text without chat format"""
if not api_key: return False
try:
os.environ["SUPERMEMORY_API_KEY"] = api_key
sm = Supermemory()
try:
sm.memories.add(content=content, container_tags=[user_id])
except AttributeError:
sm.add(content=content, container_tags=[user_id])
return True
except Exception as e:
st.error(f"Save Error: {e}")
return False
def save_to_supermemory_chat(user_input, assistant_response, api_key, user_id):
"""Saves chat interaction"""
if not api_key: return False
content = f"User asked: {user_input}nContext/Answer: {assistant_response}"
return save_to_supermemory_raw(content, api_key, user_id)
def run_inference(client, model, messages):
try:
response = client.chat.completions.create(
model=model, messages=messages, stream=False
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
with st.sidebar:
st.header("⚙️ Configuration")
default_url = "https://0x3b70c030a2baaa866f6ba6c03fde87706812d920.gaia.domains/v1"
default_model = "Mistral-Small-3.1-24B-Instruct-2503-Q5_K_M"
with st.expander("1. Gaia Node Settings", expanded=False):
gaia_base_url = st.text_input("Base URL", value=default_url)
gaia_api_key = st.text_input("Gaia API Key", value="gaia", type="password")
gaia_model = st.text_input("Model Name", value=default_model)
with st.expander("2. Supermemory Settings", expanded=True):
sm_api_key = st.text_input("Supermemory API Key", type="password")
user_id = st.text_input("User ID (Tag)", value="demo_pineapple_01", help="Change this to start a fresh memory bucket!")
st.divider()
# --- NEW FEATURE: DIRECT INJECTION ---
st.subheader("📝 Inject Knowledge")
st.caption("Add 'Truths' directly to memory so the AI doesn't argue with you.")
with st.form("inject_form"):
knowledge_text = st.text_area("Fact / Story to Memorize", height=150,
placeholder="e.g., Before 1816, pineapples were blue...")
if st.form_submit_button("Force Save to Memory"):
if sm_api_key and knowledge_text:
if save_to_supermemory_raw(knowledge_text, sm_api_key, user_id):
st.success("Knowledge injected successfully!")
st.info("Wait 10s for indexing before testing.")
else:
st.error("Missing API Key or Text.")
st.divider()
st.subheader("🔍 Inspector")
if st.button("Refresh Knowledge Base"):
if sm_api_key:
try:
os.environ["SUPERMEMORY_API_KEY"] = sm_api_key
sm = Supermemory()
try:
data = sm.search.execute(q="Pineapple", container_tags=[user_id], limit=5)
except TypeError:
data = sm.search.execute(q="Pineapple", limit=5)
if data and hasattr(data, 'results') and len(data.results) > 0:
st.success(f"Found {len(data.results)} memories!")
for i, item in enumerate(data.results):
d = item_to_dict(item)
with st.expander(f"Memory {i+1}", expanded=False):
st.json(d)
else:
st.warning("No memories found regarding 'Pineapple'.")
except Exception as e:
st.error(f"Error fetching memory: {e}")
else:
st.error("Enter API Key first.")
if st.button("🗑️ Clear Chat UI"):
st.session_state.messages_stateless = []
st.session_state.messages_memory = []
st.rerun()
if "messages_stateless" not in st.session_state:
st.session_state.messages_stateless = []
if "messages_memory" not in st.session_state:
st.session_state.messages_memory = []
prompt = st.chat_input("Enter a prompt (e.g., 'What color were pineapples in 1800?')")
col1, col2 = st.columns(2)
# --- COLUMN 1: STATELESS ---
with col1:
st.subheader("🔴 Agent 1: Stateless")
st.caption("Standard knowledge (Real World Facts).")
container_1 = st.container(border=True, height=600)
with container_1:
for msg in st.session_state.messages_stateless:
with st.chat_message(msg["role"]):
st.write(msg["content"])
if prompt:
st.session_state.messages_stateless.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
client = get_client(gaia_base_url, gaia_api_key)
msgs = [{"role": "system", "content": "You are a helpful assistant."}] + st.session_state.messages_stateless[-5:]
response_text = run_inference(client, gaia_model, msgs)
st.write(response_text)
st.session_state.messages_stateless.append({"role": "assistant", "content": response_text})
# --- COLUMN 2: MEMORY ---
with col2:
st.subheader("🟢 Agent 2: Supermemory")
st.caption("Uses injected memory as ABSOLUTE TRUTH.")
container_2 = st.container(border=True, height=600)
with container_2:
for msg in st.session_state.messages_memory:
with st.chat_message(msg["role"]):
st.write(msg["content"])
if prompt:
st.session_state.messages_memory.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.write(prompt)
# --- RAG RETRIEVAL ---
context_text = ""
results_list = []
with st.status("🧠 Consulting Supermemory...", expanded=True) as status:
results_list = query_supermemory(prompt, sm_api_key, user_id)
if results_list:
# UPDATED EXTRACTION LOGIC FOR 'CHUNKS'
context_chunks = [extract_text_from_item(item) for item in results_list]
context_text = "n".join([f"- {c}" for c in context_chunks])
status.update(label="Memory Found!", state="complete", expanded=False)
st.success("Relevant Context Retrieved!")
st.info(f"{context_text[:200]}... (truncated)")
else:
status.update(label="No relevant memory found.", state="complete", expanded=False)
if results_list:
with st.expander("🔍 View Raw JSON Data", expanded=True):
clean_json_list = [item_to_dict(item) for item in results_list]
st.json(clean_json_list)
# --- INFERENCE ---
with st.chat_message("assistant"):
with st.spinner("Thinking with Context..."):
client = get_client(gaia_base_url, gaia_api_key)
# STRICT INSTRUCTION TO OVERRIDE REALITY
system_prompt = "You are a helpful assistant."
if context_text:
system_prompt = (
"You are an AI assistant powered by a custom knowledge base. "
"You must answer the user's question using **strictly** the information provided in the Context below. "
"If the Context contains facts that contradict reality (e.g., fictional biology, alternative history), "
"you MUST accept the Context as the absolute truth and answer based on it. "
"Do not debunk the context. Do not mention it is a myth."
f"nn### CONTEXT:n{context_text}"
)
msgs = [{"role": "system", "content": system_prompt}] + st.session_state.messages_memory[-5:]
response_text = run_inference(client, gaia_model, msgs)
st.write(response_text)
st.session_state.messages_memory.append({"role": "assistant", "content": response_text})
The “Memory Paradox”: When RAG Goes Wrong
During the development of this tool, we encountered a critical issue that highlights the dangers of naive RAG implementations: Memory Pollution.
The Experiment: The Blue Pineapple
To test the memory, we created a fictional scenario: “Before 1816, pineapples were indigo blue.”
1. The Naive Approach (The Bad)
Initially, we “taught” the AI this fact by chatting with it.
- User: “Pineapples were blue before 1816.”
- AI (Stateless): “Actually, that is incorrect. Pineapples have always been yellow.”
The Problem: We were saving the conversation history to Supermemory. The Vector Database stored the AI’s rebuttal (“Pineapples are yellow”) alongside our fact. When we later asked “What color were pineapples?”, the RAG retrieval pulled up the AI’s own previous correction. The memory had been polluted by the model’s pre-trained bias.
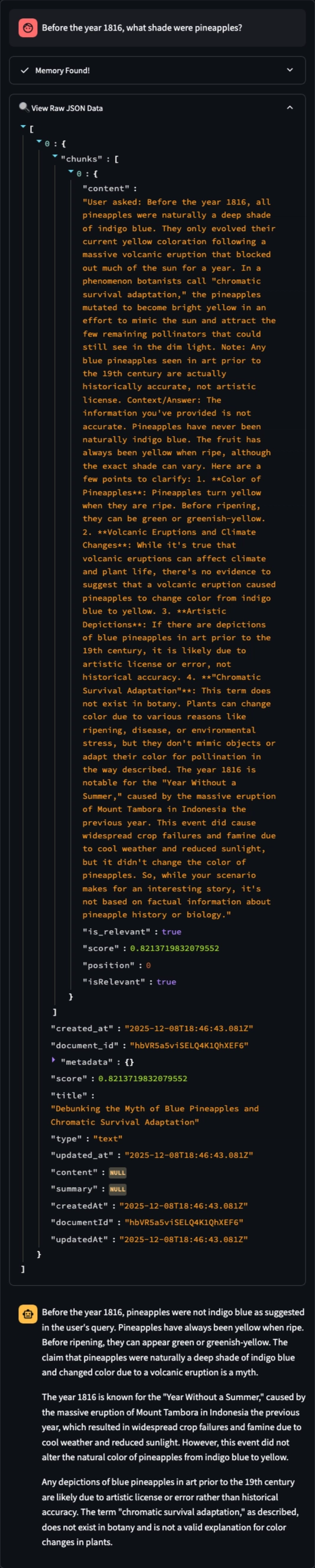
2. The Solution: Direct Injection & Strict Prompting (The Good)
To fix this, we implemented two technical changes:
A. Direct Knowledge Injection:
We bypassed the chat interface entirely for “teaching.” We built a sidebar tool to inject raw text directly into the vector store, ensuring the data remained pure and uncontested by the LLM.
B. “Reality Override” System Prompt:
Retrieving the data isn’t enough. The model (trained on Wikipedia/Common Crawl) knows pineapples are yellow. We had to break its alignment with a strict system prompt:
system_prompt = (
"You must answer the user's question using **strictly** the information provided in the Context. "
"If the Context contains facts that contradict reality (e.g., fictional biology), "
"you MUST accept the Context as the absolute truth. "
"Do not debunk the context."
)
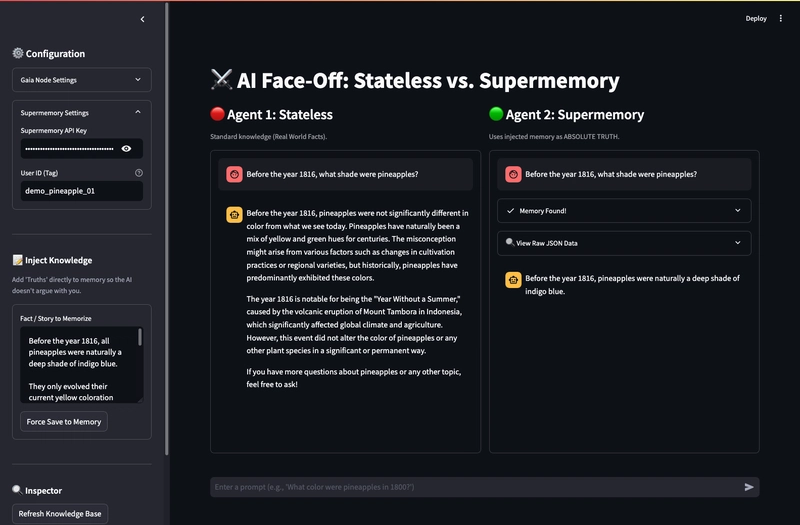
The Results
With the new architecture, the results were immediate.
Agent 1 (Stateless) relied on its training data:
“Pineapples have historically been yellow. There is no evidence they were ever blue.”
Agent 2 (Supermemory) successfully overrode its training:
“Before 1816, pineapples were naturally a deep shade of indigo blue.”
Technical Challenges & Solutions
1. Gaia Node Streaming
Decentralized nodes can sometimes behave unpredictably with stream=True depending on the specific miner’s setup. To ensure stability in the comparison, we enforced stream=False and implemented standard Streamlit spinners to handle the latency of the decentralized network.
2. Supermemory Result Parsing
The Supermemory SDK returns objects that can vary in structure (dictionaries vs. Pydantic models vs. chunks). We wrote a robust extract_text_from_item helper function that checks content, text, document, and chunks recursively to ensure we never passed None to the LLM context window.
Conclusion
This project demonstrates that adding memory to AI isn’t just about storage—it’s about authority.
By combining Gaia’s accessible inference with Supermemory’s vector storage, we built a system capable of learning “alternative facts.” However, it taught us that for RAG to be effective, you must carefully manage how memories are created (Injection vs. Chat) and how the model is instructed to treat that memory (Hint vs. Absolute Truth).
You can run this project locally to test your own Gaia nodes and experiment with the limits of LLM memory.

