Building High-Performance Time Series on SQLite with Go: UUIDv7, sqlc, and libSQL
A practical, end-to-end guide to implementing production-grade time series on SQLite/libSQL using Go.
Together we’ll design a schema optimized for speed and scale (UUIDv7 as BLOB primary keys plus millisecond INTEGER timestamps), generate type-safe data access with sqlc, and wire it to libSQL for embedded replicas and network sync. Along the way, we’ll fold it into a clean hexagonal architecture (domain → repository → service), add migrations with goose, a CLI with Cobra, and robust tests with Testify. We’ll also look at moving averages, gap detection, batching, indexing, and how to evolve your model with domain-specific metadata (like EU electricity market attributes) without sacrificing performance.
Ready? Buckle-up.
Why SQLite (and libSQL) for Time Series?
If we are honest with ourselves most time series workloads aren’t petabytes. They’re append-heavy, read-range-heavy, and demand low operational friction.
SQLite gives you: simplicity, portability, blazing local reads, and powerful SQL (window functions, CTEs). libSQL (by the great folks at turso) builds on that with embedded replicas and sync, giving us the tools to read locally at microsecond latency and still keep a remote primary. Welcome to the future.
Typical concerns such as “SQLite can’t scale” fade when you design for range queries, batch writes, and pragmatic partitioning. With the right patterns, it’s a serious store for analytics, trading/backtesting, observability, and IoT.
Architecture at a Glance
I could keep this article terse and to the point, however I want to show what it takes to implement such a system in a real production-ready application.
We’ll keep strict boundaries using hexagonal architecture: domain types and interfaces in the center, service orchestrating business logic, and infrastructure adapters (libSQL/sqlc) on the edge.
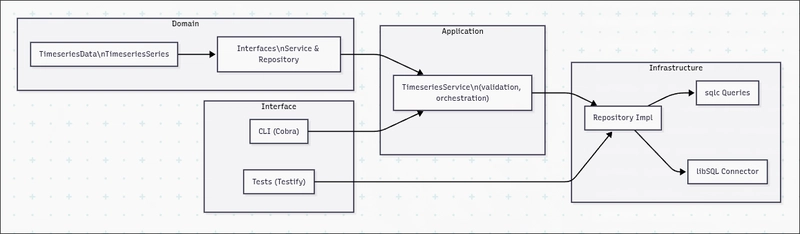
This shape pays dividends: testable core, swappable adapters, and clear ownership of concerns.
Data Model: UUIDv7 + Millisecond Timestamps
The winning combo:
-
Primary key: UUIDv7 stored as
BLOB(16)(compact, time-ordered inserts) -
Timestamp:
INTEGERUnix epoch in milliseconds (fast arithmetic + range filters) - Essential indexes for range scans and sorting
Core Tables (excerpt)
-- Generic timeseries table
CREATE TABLE IF NOT EXISTS timeseries_data (
id BLOB PRIMARY KEY,
series_id TEXT NOT NULL,
metric TEXT NOT NULL,
ts INTEGER NOT NULL, -- epoch ms
value REAL NOT NULL,
metadata TEXT,
created_at INTEGER NOT NULL DEFAULT (unixepoch('now') * 1000)
);
CREATE INDEX IF NOT EXISTS idx_timeseries_series_ts
ON timeseries_data(series_id, ts);
CREATE INDEX IF NOT EXISTS idx_timeseries_series_metric_ts
ON timeseries_data(series_id, metric, ts);
CREATE INDEX IF NOT EXISTS idx_timeseries_ts ON timeseries_data(ts);
-- Series metadata (extensible)
CREATE TABLE IF NOT EXISTS timeseries_series (
id BLOB PRIMARY KEY,
series_id TEXT UNIQUE NOT NULL,
name TEXT NOT NULL,
description TEXT,
data_type TEXT NOT NULL DEFAULT 'numeric',
retention_days INTEGER,
downsample_interval INTEGER,
created_at INTEGER NOT NULL DEFAULT (unixepoch('now') * 1000),
updated_at INTEGER NOT NULL DEFAULT (unixepoch('now') * 1000),
-- Optional domain-specific fields (e.g., EU electricity market)
market_type TEXT,
data_source TEXT,
geographic_scope TEXT,
data_frequency TEXT,
regulatory_compliance TEXT,
quality_standard TEXT,
unit_of_measure TEXT,
timezone TEXT,
bidding_zone TEXT,
contract_type TEXT,
data_provider TEXT
);
Why UUIDv7? It keeps inserts mostly sequential (timestamp prefix), minimizing B-tree churn compared to random UUIDv4, and you still get global uniqueness.
Migrations with goose
Embed and run migrations in SQLite mode. You can target libSQL by opening the libSQL connector; the SQL dialect remains SQLite.
import (
"context"
"database/sql"
"os"
"github.com/pressly/goose/v3"
_ "github.com/tursodatabase/go-libsql"
)
func Migrate(db *sql.DB) error {
prov, err := goose.NewProvider(goose.DialectSQLite3, db, os.DirFS("internal/infrastructure/adapters/db/migrations"))
if err != nil { return err }
_, err = prov.Up(context.Background())
return err
}
Type-Safe Data Access with sqlc
sqlc turns your SQL into compile-time-checked Go. Configure it to read migrations and query files, then generate Queries with typed params/rows.
# sqlc.yaml (excerpt)
version: "2"
sql:
- schema: "internal/infrastructure/adapters/db/migrations"
queries: "internal/infrastructure/adapters/db/queries"
engine: "sqlite"
gen:
go:
package: "db"
out: "internal/infrastructure/adapters/db"
emit_prepared_queries: true
emit_json_tags: true
Query Examples (excerpt)
-- name: InsertTimeseriesData :exec
INSERT INTO timeseries_data (id, series_id, metric, ts, value, metadata)
VALUES (?, ?, ?, ?, ?, ?);
-- name: GetTimeseriesDataRange :many
SELECT id, series_id, metric, ts, value, metadata, created_at
FROM timeseries_data
WHERE series_id = @series_id
AND metric = @metric
AND ts >= @start_ts AND ts <= @end_ts
ORDER BY ts ASC;
-- name: GetTimeseriesStats :one
SELECT COUNT(*) AS total_records,
MIN(ts) AS earliest_ts,
MAX(ts) AS latest_ts,
MIN(value) AS min_value,
MAX(value) AS max_value,
AVG(value) AS avg_value,
SUM(value) AS sum_value
FROM timeseries_data
WHERE series_id = @series_id AND metric = @metric
AND ts >= @start_ts AND ts <= @end_ts;
-- name: GetTimeseriesGaps :many
SELECT ts AS gap_start,
LEAD(ts) OVER (ORDER BY ts) AS gap_end,
(LEAD(ts) OVER (ORDER BY ts) - ts) AS gap_duration_ms
FROM timeseries_data
WHERE series_id = @series_id AND metric = @metric
AND ts >= @start_ts AND ts <= @end_ts
AND (LEAD(ts) OVER (ORDER BY ts) - ts) > @threshold_ms
ORDER BY ts;
Tip: named parameters (@param) make sqlc’s SQLite parser happier than ? in complex expressions.
libSQL Connector and Repository
Open an embedded replica or local file; both speak the SQLite dialect. The repository adapts domain models to sqlc params and rows, performs batch inserts in a transaction, and exposes analytics (stats, gaps, moving average).
// Opening libSQL (embedded replica or local file)
conn, err := libsql.NewEmbeddedReplicaConnector(dbPath, primaryURL, libsql.WithAuthToken(authToken))
db := sql.OpenDB(conn)
q := dbpkg.New(db) // sqlc-generated
// Batch insert with a transaction
func (r *TimeseriesRepositoryImpl) InsertBatch(points []domain.TimeseriesData) error {
if len(points) == 0 { return nil }
tx, err := r.Db.BeginTx(context.Background(), nil)
if err != nil { return err }
defer tx.Rollback()
qtx := r.Q.WithTx(tx)
for _, p := range points {
var meta []byte
if len(p.Metadata) > 0 { meta, _ = json.Marshal(p.Metadata) }
params := dbpkg.InsertTimeseriesDataParams{
ID: ids.MustToBytes(p.ID),
SeriesID: p.SeriesID,
Metric: p.Metric,
Ts: p.Timestamp.UnixMilli(),
Value: p.Value,
Metadata: sql.NullString{String: string(meta), Valid: len(meta) > 0},
}
if err := qtx.InsertTimeseriesData(context.Background(), params); err != nil {
return err
}
}
return tx.Commit()
}
Mapping functions convert sqlc rows to domain types (time.Unix(ms/1000, (ms%1000)*1e6) for millisecond timestamps) and unwrap sql.Null* safely.
Service Layer and CLI
The service validates inputs, orchestrates repository calls, and surfaces errors as domain types. A small Cobra CLI wires the service so you can:
- create/list series
- ingest single/batch data points
- query ranges and latest values
- compute statistics and moving averages
- detect gaps
This is invaluable for ops and quick debugging.
Analytics: Moving Average and Gap Detection
SQLite’s window functions make rolling analytics trivial:
SELECT ts,
value,
AVG(value) OVER (
ORDER BY ts ROWS BETWEEN @window_size PRECEDING AND CURRENT ROW
) AS moving_avg
FROM timeseries_data
WHERE series_id = @series_id AND metric = @metric
AND ts >= @start_ts AND ts <= @end_ts
ORDER BY ts;
Gap detection is a classic LEAD(ts) trick (see queries above). It scales well with the right index.
Extensibility: Domain-Specific Series Metadata
Need to annotate series for the EU electricity market? Add optional fields to timeseries_series (market type, bidding zone, unit of measure, etc.). Expose filtered queries like GetSeriesByMarketType, GetSeriesByDataSource, and GetSeriesByBiddingZone. Because the time-indexed fact table (timeseries_data) stays lean, reads remain fast.
Performance Playbook
- Batch inserts inside a transaction (dramatic speedup over per-row commits).
-
Composite indexes
(series_id, metric, ts)for range scans and ordered streaming. - Keep timestamps as INTEGER (epoch ms) for arithmetic and filters.
- Embedded replicas (libSQL) for ultra-fast local reads; sync periodically.
-
VACUUM periodically and consider
PRAGMAtuning if your workload warrants it. - Partitioning by month (separate tables) when datasets grow into billions of rows; union views for cross-partition queries.
- Downsampling to summarize old data (hourly/daily rollups); keep raw for a bounded horizon.
Testing Strategy
- Use an in-memory SQLite database for fast, deterministic tests.
- Create the minimal schema in test setup and call repository methods directly.
- Assert ordering, edge cases (empty ranges), and analytics correctness with table-driven tests.
testify/suite helps keep setup/teardown tidy. Aim to test the service with realistic data distributions.
Trade-offs and Caveats
- SQLite isn’t a distributed time series database. For cross-region writes or petascale retention, pick tools built for that.
- Window functions on huge spans can be expensive, bucket results, pre-aggregate, or window over limited frames.
- Schema evolution: use migrations thoughtfully; keep your fact table narrow and push descriptive fields to metadata.
Checklist: Production Readiness
- Schema: UUIDv7 BLOB PK, INTEGER ms timestamps, critical indexes
- Data access: sqlc-generated queries, named params, prepared statements
- Architecture: domain interfaces, repository impl, service orchestration
- CLI/Automation: Cobra for ops workflows (ingest, query, analytics)
- Migrations: goose wired into startup/tests
- Performance: batch inserts, local replicas, periodic vacuum, plan for downsampling/partitioning
- Observability: logging and tracing around ingest/queries for p95 monitoring
Wrap-up
Time series on SQLite can be elegant and fast when you respect its strengths: compact on-disk format, smart indexing, mature SQL, and zero-ops deployment. With libSQL’s replicas, sqlc’s type-safety, and a clean hexagonal design, you’ll ship something that’s both robust today and adaptable tomorrow.
If you’re already imagining your first batch job and a couple of windowed queries… good. That’s the point. Start small, measure, iterate … and let the simplicity compound.
Mini Benchmark Harness (Single vs Batch, With/Without Index)
It’s one thing to say “batching is faster.” It’s another to see it. Here’s a tiny harness you can adapt to measure:
package main
import (
"context"
"database/sql"
"encoding/hex"
"fmt"
"math/rand"
"time"
_ "github.com/tursodatabase/go-libsql" // driver name: libsql
)
// uuidv7ish generates 16 bytes with a millisecond timestamp prefix (not a full RFC implementation).
func uuidv7ish(ts time.Time) []byte {
var u [16]byte
ms := uint64(ts.UnixMilli())
u[0] = byte(ms >> 40)
u[1] = byte(ms >> 32)
u[2] = byte(ms >> 24)
u[3] = byte(ms >> 16)
u[4] = byte(ms >> 8)
u[5] = byte(ms)
rand.Read(u[6:])
u[6] = (u[6] & 0x0f) | 0x70 // version 7
u[8] = (u[8] & 0x3f) | 0x80 // variant
return u[:]
}
type point struct {
id []byte
ts int64
value float64
}
func ensureSchema(db *sql.DB, withIndex bool) error {
stmts := []string{
"DROP TABLE IF EXISTS timeseries_data;",
`CREATE TABLE timeseries_data (
id BLOB PRIMARY KEY,
series_id TEXT NOT NULL,
metric TEXT NOT NULL,
ts INTEGER NOT NULL,
value REAL NOT NULL,
metadata TEXT,
created_at INTEGER NOT NULL DEFAULT (unixepoch('now') * 1000)
);`,
}
if withIndex {
stmts = append(stmts,
"CREATE INDEX IF NOT EXISTS idx_series_ts ON timeseries_data(series_id, ts);",
"CREATE INDEX IF NOT EXISTS idx_series_metric_ts ON timeseries_data(series_id, metric, ts);",
)
}
for _, s := range stmts {
if _, err := db.Exec(s); err != nil { return err }
}
return nil
}
func gen(n int, series, metric string, start time.Time, step time.Duration) []point {
out := make([]point, n)
t := start
for i := 0; i < n; i++ {
out[i] = point{
id: uuidv7ish(t),
ts: t.UnixMilli(),
value: 1000 + rand.Float64()*10,
}
t = t.Add(step)
}
return out
}
func insertSingle(db *sql.DB, series, metric string, pts []point) (time.Duration, error) {
start := time.Now()
for _, p := range pts {
if _, err := db.Exec(
"INSERT INTO timeseries_data (id, series_id, metric, ts, value) VALUES (?, ?, ?, ?, ?)",
p.id, series, metric, p.ts, p.value,
); err != nil { return 0, err }
}
return time.Since(start), nil
}
func insertBatch(db *sql.DB, series, metric string, pts []point, batchSize int) (time.Duration, error) {
start := time.Now()
tx, err := db.BeginTx(context.Background(), nil)
if err != nil { return 0, err }
stmt, err := tx.Prepare("INSERT INTO timeseries_data (id, series_id, metric, ts, value) VALUES (?, ?, ?, ?, ?)")
if err != nil { return 0, err }
defer stmt.Close()
count := 0
for _, p := range pts {
if _, err := stmt.Exec(p.id, series, metric, p.ts, p.value); err != nil { return 0, err }
count++
if count%batchSize == 0 {
if err := tx.Commit(); err != nil { return 0, err }
tx, err = db.BeginTx(context.Background(), nil)
if err != nil { return 0, err }
stmt, err = tx.Prepare("INSERT INTO timeseries_data (id, series_id, metric, ts, value) VALUES (?, ?, ?, ?, ?)")
if err != nil { return 0, err }
}
}
if err := tx.Commit(); err != nil { return 0, err }
return time.Since(start), nil
}
func main() {
// Use a file DB for realistic I/O; switch to :memory: for upper-bound insert speeds.
db, err := sql.Open("libsql", "file:bench.db")
if err != nil { panic(err) }
defer db.Close()
series := "bench:series"
metric := "value"
n := 50000
pts := gen(n, series, metric, time.Now().Add(-time.Hour), time.Second)
// Variant 1: no index, single-row inserts
_ = ensureSchema(db, false)
d1, err := insertSingle(db, series, metric, pts)
if err != nil { panic(err) }
fmt.Printf("no-index single: %v (%.1f inserts/sec)n", d1, float64(n)/d1.Seconds())
// Variant 2: no index, batched inserts
_ = ensureSchema(db, false)
d2, err := insertBatch(db, series, metric, pts, 1000)
if err != nil { panic(err) }
fmt.Printf("no-index batched: %v (%.1f inserts/sec)n", d2, float64(n)/d2.Seconds())
// Variant 3: with index, single-row inserts
_ = ensureSchema(db, true)
d3, err := insertSingle(db, series, metric, pts)
if err != nil { panic(err) }
fmt.Printf("index single: %v (%.1f inserts/sec)n", d3, float64(n)/d3.Seconds())
// Variant 4: with index, batched inserts
_ = ensureSchema(db, true)
d4, err := insertBatch(db, series, metric, pts, 1000)
if err != nil { panic(err) }
fmt.Printf("index batched: %v (%.1f inserts/sec)n", d4, float64(n)/d4.Seconds())
// sanity: print a sample id
fmt.Println("sample id:", hex.EncodeToString(pts[0].id))
}
Notes:
- WAL mode and synchronous settings change results. Keep them constant across runs.
- File-backed DBs show more realistic effects of fsync; in-memory shows upper bounds.
- Expect batched inserts to outperform single-row inserts by an order of magnitude, and indexes to slow inserts but speed reads.
Quickstart (End-to-End)
Here’s a focused “from zero to query” path you can adapt.
1) Dependencies
- Go 1.24+
github.com/tursodatabase/go-libsqlgithub.com/pressly/goose/v3github.com/sqlc-dev/sqlcgithub.com/spf13/cobragithub.com/stretchr/testify
2) Migrate
# create and migrate a local SQLite/libSQL database (adapt paths/commands to your setup)
export LIBSQL_DB_PATH=./local.db
# Example using goose directly (adjust DSN):
goose -dir ./migrations sqlite3 "$LIBSQL_DB_PATH" up
3) Create a series (example pattern)
INSERT INTO timeseries_series (
id, series_id, name, description, data_type, unit_of_measure, created_at, updated_at
) VALUES (
x'00112233445566778899AABBCCDDEEFF',
'price:btcusd',
'BTC-USD Price',
'Spot price feed',
'numeric',
'USD',
unixepoch('now') * 1000,
unixepoch('now') * 1000
);
4) Ingest a couple of points (SQL pattern)
INSERT INTO timeseries_data (id, series_id, metric, ts, value)
VALUES
(x'00112233445566778899AABBCCDDEE01', 'price:btcusd', 'mid', strftime('%s','2025-01-01T00:00:00Z')*1000, 42000),
(x'00112233445566778899AABBCCDDEE02', 'price:btcusd', 'mid', strftime('%s','2025-01-01T00:00:10Z')*1000, 42005);
5) Query a range (SQL pattern)
SELECT ts, value
FROM timeseries_data
WHERE series_id = 'price:btcusd'
AND metric = 'mid'
AND ts BETWEEN strftime('%s','2025-01-01T00:00:00Z')*1000 AND strftime('%s','2025-01-01T00:01:00Z')*1000
ORDER BY ts ASC;
6) Analytics (SQL pattern)
-- statistics
SELECT COUNT(*) AS total_records,
MIN(ts) AS earliest_ts,
MAX(ts) AS latest_ts,
MIN(value) AS min_value,
MAX(value) AS max_value,
AVG(value) AS avg_value
FROM timeseries_data
WHERE series_id = 'price:btcusd'
AND metric = 'mid'
AND ts BETWEEN strftime('%s','2025-01-01T00:00:00Z')*1000 AND strftime('%s','2025-01-01T00:10:00Z')*1000;
-- moving average (window = 5)
SELECT ts,
value,
AVG(value) OVER (
ORDER BY ts ROWS BETWEEN 5 PRECEDING AND CURRENT ROW
) AS moving_avg
FROM timeseries_data
WHERE series_id = 'price:btcusd'
AND metric = 'mid'
AND ts BETWEEN strftime('%s','2025-01-01T00:00:00Z')*1000 AND strftime('%s','2025-01-01T00:10:00Z')*1000
ORDER BY ts;
Downsampling & Partitioning (When and How)
You don’t need these at the start. But when row counts creep into hundreds of millions, they help.
-
Downsampling: create a
timeseries_downsampledtable keyed by(series_id, bucket_ts)and roll up aggregates (count, min, max, avg). Run a periodic job to summarize old data, keep raw only for a recent horizon (e.g., last 90 days). -
Partitioning: monthly tables, e.g.,
timeseries_data_2025_01. A simple viewtimeseries_data_allcanUNION ALLrecent partitions for transparent queries. Migrations can create/drop the next/previous month’s partition.
Trade-off: more DDL and query orchestration, but faster inserts and smaller indexes per partition.
PRAGMA & Tuning Tips (Use Sparingly)
-
PRAGMA journal_mode=WAL;often helps concurrent readers. -
PRAGMA synchronous=NORMAL;is a pragmatic default for many workloads. -
PRAGMA cache_sizeandmmap_sizecan help large reads; measure before/after. - Keep an eye on index bloat; periodic
VACUUM;is fine (schedule off-peak).
Don’t shotgun PRAGMAs. Change one thing, benchmark, record.
EU Electricity Market Metadata Patterns
If you’re in power markets, you’ll eventually need series-level descriptors (bidding zone, contract type, compliance flags…). Keep the fact table lean and push descriptors into the timeseries_series table as optional columns. Offer filtered lookups:
GetSeriesByMarketType(marketType)GetSeriesByDataSource(dataSource)GetSeriesByBiddingZone(zone)
Because your queries filter on series_id and metric (and ts), this metadata doesn’t slow down hot paths. It does make the system navigable.
Pitfalls & FAQ
- “Why not TEXT timestamps?” Parsing hurts. Use INTEGER ms for math and comparisons.
- “Do I need UUIDv7 everywhere?” For time series PKs: yes, it significantly helps insertion order and index locality over UUIDv4.
- “sqlc chokes on some window syntax.” Prefer named parameters and straightforward frames. If a particular window function gives the parser a hard time, simplify the query shape or compute in the service for now.
- “Do I need a time-series DB instead?” If you need elastic sharding, compression, and multi-tenant hot rollups at petascale—yes. Otherwise, SQLite + good patterns goes surprisingly far.
Action Steps
- Start with a single table + the three key indexes.
- Add sqlc and wire a repository with transactions for batch inserts.
- Build CLI verbs to ingest and query; they double as ops tools.
- Add moving average + gap detection; validate against synthetic data.
- Measure. Only then, consider downsampling/partitioning.
