Building an “Unstoppable” Serverless Payment System on AWS (Circuit Breaker Pattern)
Building an “Unstoppable” Serverless Payment System on AWS
What happens when your payment gateway goes down? In a traditional app, the user sees a spinner, then a “500 Server Error,” and you lose the sale.
I wanted to build a system that refuses to crash. Even if the backend database is on fire, the user’s order should be accepted, queued, and processed automatically when the system heals.
Here is how I implemented the Circuit Breaker Pattern using AWS Step Functions, Java Lambda, and Event-Driven Architecture—without provisioning a single server.
The Tech Stack
I chose a hybrid, cloud-native stack to enforce strict decoupling between the Frontend and the Backend.
- Frontend: Python (Streamlit) – Acts as the Store & Admin Dashboard.
- Orchestration: AWS Step Functions – The “Brain” handling the logic.
- Compute: AWS Lambda (Java 11) – The “Worker” handling business logic.
- State Store: Amazon DynamoDB – Stores circuit status (Open/Closed) and Order History.
- Resiliency: Amazon SQS – The “Parking Lot” for failed orders.
- Observability: Grafana Cloud (Loki) – Log aggregation.
- Infrastructure: Terraform – Complete IaC.
Note : Use terraform to manage resources ,best practice to keep all your resources terraform in separate file for creation/deletion/any kind of update.
The Problem: Cascading Failures
In microservices, if Service A calls Service B, and Service B hangs, Service A eventually hangs too. If thousands of users click “Pay,” your database gets hammered with retries, effectively DDoS-ing yourself.
The Solution? A Circuit Breaker.
Just like in your house: if there is a surge, the breaker trips to save the house from burning down.
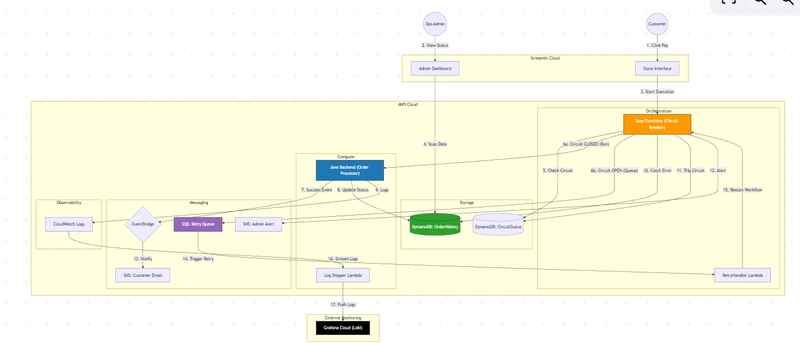
High Level Architecture:
I designed the system to handle three distinct states:
- Green Path (Closed): The backend is healthy. Orders process immediately.
- Red Path (Open): The backend is crashing. The system detects this, “Trips” the circuit, and stops sending traffic to the backend.
- Yellow Path (Recovery): Orders are routed to a Queue (SQS) to be retried later automatically.
HLD may look scary but it is will make your app unstoppable.
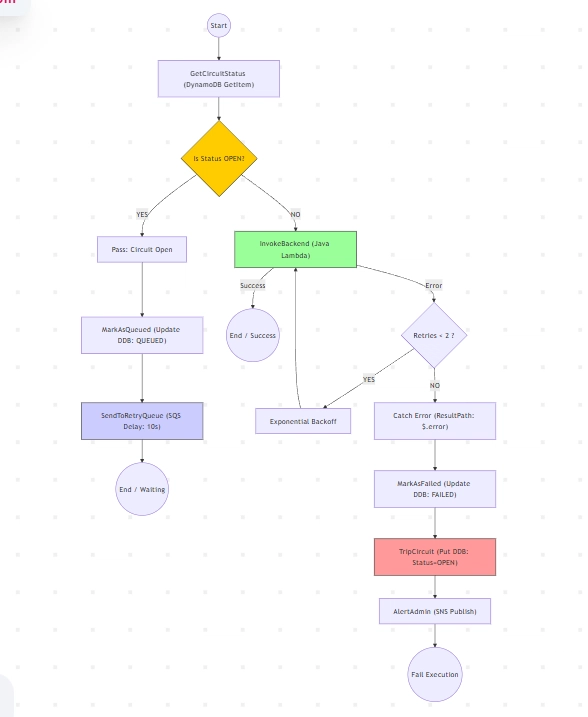
How It Works The Logic Flow :
The core of this project is an AWS Step Functions State Machine. It acts as a traffic controller.
-
The Check
Every time a user clicks “Pay,” the workflow first checks DynamoDB.
Is the Circuit Status OPEN?
If YES: Skip the backend entirely.
If NO: Proceed to the Java Lambda. -
The Execution
The workflow invokes a Java Lambda to process the payment.
Success: It updates the Order History to COMPLETED and emits an event to EventBridge (triggering a customer email via SNS).
Failure: It catches the error and retries with Exponential Backoff (Wait 1s, then 2s).
3.** The “Trip”**
If the backend fails repeatedly, the Step Function:
Writes Status: OPEN to DynamoDB.
Alerts the SysAdmin via SNS (“Critical: Circuit Tripped”).
Marks the order as FAILED in the dashboard. -
The Self-Healing (Auto-Retry)
This is the coolest part. If the circuit is Open, new orders are not rejected. They are marked as QUEUED and sent to Amazon SQS.
A “Retry Handler” Lambda listens to this queue.
It waits for a delay (e.g., 30s).It re-submits the order to the Step Function.If the backend is fixed, the order processes. If not, it goes back to the queue.
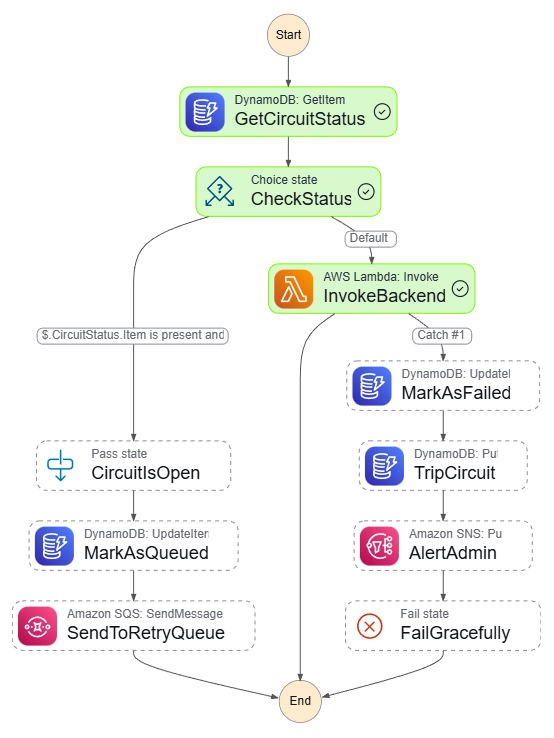
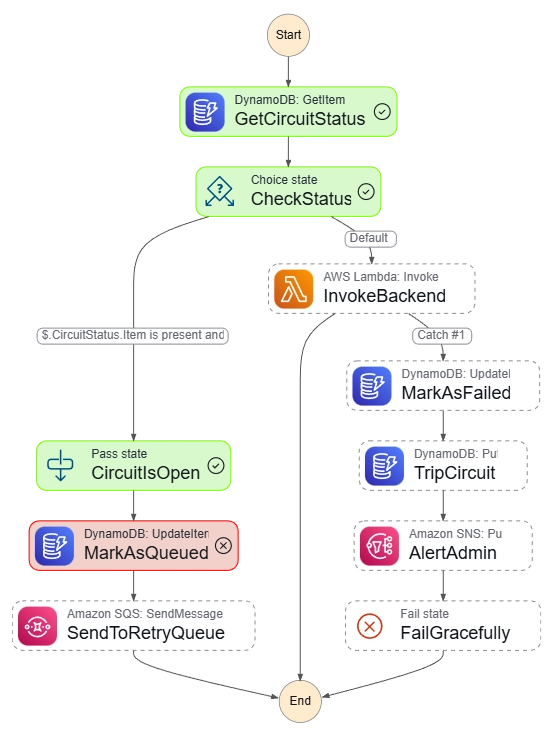
Tested Data Scenarios:
-
SUCCESS
-
CHAOS Mode
Observability & Monitoring: I integrated Grafana Cloud (Loki) to ingest logs from CloudWatch.
Streamlit Dashboard: Shows live status of orders (PENDING → COMPLETED or FAILED).
Grafana Explore: Allows deep searching of logs using {service=”order-processor”} to find specific stack traces.
Key Learnings & Trade-offs
- Complexity vs. Reliability
This architecture is more complex than a simple API call. You have more moving parts (Queues, State Machines). However, the trade-off is High Availability. The frontend never sees a crash. - The “Ghost” Data
When using Catch blocks in Step Functions, the original input (Order ID) is replaced by the Error Message. I learned to use ResultPath to preserve the original data so I could update the database even after a crash. - Cost Optimization
Step Functions Standard Workflows are expensive at scale. For production, I would switch this to Express Workflows and use ARM64 (Graviton) for the Lambdas to reduce costs by ~40%.
Application looks like:
-
Order placing UI reference
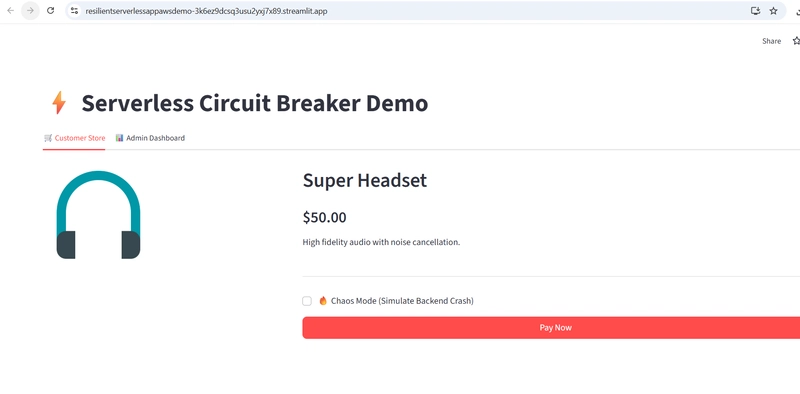
-
Admin UI
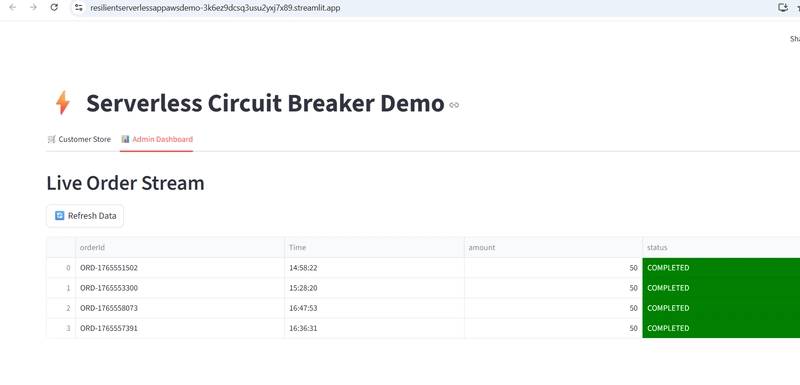
Conclusion
This project demonstrates how Event-Driven Architecture allows you to build systems that degrade gracefully. Instead of losing revenue during a crash, we simply “pause” the traffic and process it when the storm passes.
Technologies used: AWS, Java, Python, Terraform, Grafana.
Follow for more. Thanks for reading !



