API-Led Connectivity - Practical Questions Answered - Part III
Part 3 - Implementation and Design Choices
API-Led Connectivity is a proven architectural pattern for separating data, business logic, and representations across APIs. Numerous articles have been written about its advantages, but putting them into practice often raises many questions.
We looked at the basics in Part 1. In Part 2, we discussed some questions about the structure and composition of APIs.
In Part 3, we’ll tackle real-world questions, often about implementation and design choices.
1. Should a System API return a domain model or a one-to-one mapping of data from SoR?
Domain model is better, but mapping is fine in specific cases
It’s better to return a domain model because it makes things more abstract and stable. However, sometimes one-to-one mappings might be acceptable for internal or CRUD-based tasks.
System APIs work best when they expose a clean, stable domain model that abstracts the underlying System of Record. This approach has important architectural advantages:
-
Abstraction and decoupling: It protects consumers (like Process APIs) from backend volatility. For example, if a field in the SoR is renamed or its structure changes, your domain model stays the same and the API contract is safe.
-
Clear semantics: SoR schemas don’t always show what the business wants, but they do show what is technically possible. A domain model helps show things like Customer, Order, or Invoice in ways that make sense for the business and are easier for other APIs to consume.
-
Cross-system consistency: When multiple SoRs model similar entities in different ways, System APIs can standardize and expose them in a single format, which makes integration easier and cleaner.
Direct SoR mapping is okay in some specific scenarios:
- Admin or CRUD interfaces: Tools that need full control over raw fields and behaviors may need structures that don’t change.
- Legacy migration or pass-through access: If the purpose of the System API is proxying and replicating old systems without data transformation.
Even in those cases, it’s best to keep them separate and document trade-offs.Tight coupling can expose internal parts and make integrations less stable.
2. Should Process or Experience APIs use domain models from lower layers, or should they map them to their own internal service models or DTOs?
Better to map, but direct use is sometimes okay
By default, mapping makes things clearer, separates concerns, and adds a layer of abstractions. Only use models again when they are stable, shared within the domain, and owned within the same boundary.
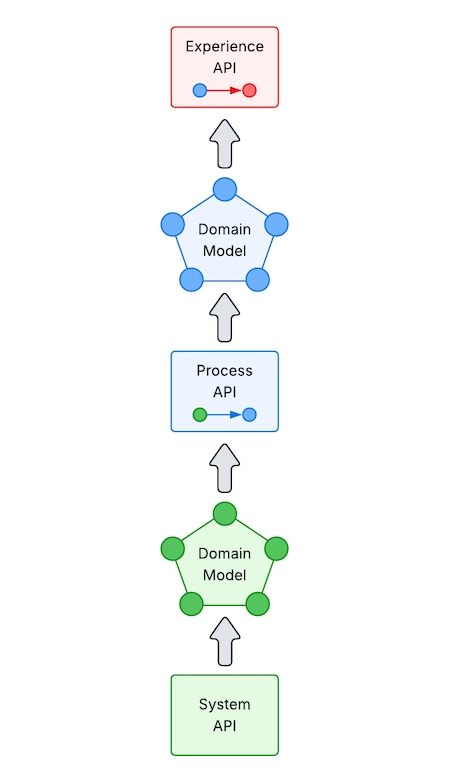
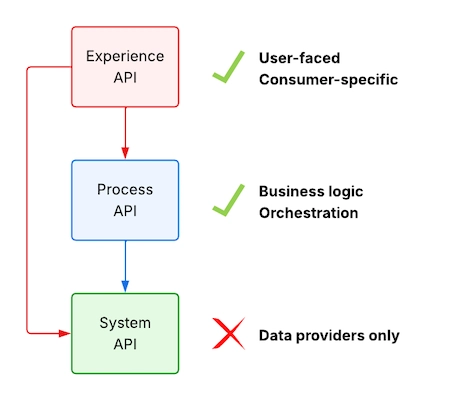
Think of each API layer as a boundary with its own language:
- System APIs are based on SoRs.
- Process APIs show how business logic and orchestration work.
- Experience APIs meet the needs of consumers.
Mapping between models at each layer helps preserve that separation of concerns.
System API domain models: Use or Map in Process APIs?
It’s best to map to internal models (DTOs).
Why?
- Decoupling: System APIs expose data that can be reused, but Process APIs often need to change, add to, or combine that data for business logic. With mapping, you can change things without getting stuck with the way the System API is set up.
- Resilience to change: If the System API changes (for example, by adding fields or renaming attributes), the DTO layer protects your Process API.
- Semantic clarity: Process APIs use the language of business processes, not systems. Mapping helps show what you want to do.
Process API domain models: Use or Map in Experience APIs?
Again, mapping is better because Experience APIs should focus on consumer needs.
Why?
- Tailored payloads: Mobile apps, web portals, and partner systems often need formats or field names that are different from each other.
- Performance optimization: You might want to remove unused fields, flatten nested structures, or make content more relevant to consumers.
- Channel independence: If two Experience APIs (like mobile and web) use the same Process API, mapping lets each one develop independently.
There are occasions when it is acceptable - and even better - to reuse upstream models without mapping them to internal DTOs for the sake of simplicity, performance, or alignment.
- Read-Only, Pass-Through APIs: If a Process or Experience API is acting as a transparent proxy, passing data without changing or adding to it, mapping may not be needed. For instance, a customer lookup API that gets basic profile information from CRM without any business logic in between.
-
Stable, Shared Canonical Models: When teams share a well-defined, versioned domain model (like a shared
CustomerDtoorOrderModel) with clear ownership and contract stability, it’s okay to reuse it across layers. This happens a lot when there is a centralized modeling team or a mature domain design across services. -
Internal Tools or Trusted Consumers: In APIs that are only for internal use (like dev dashboards and admin tools), where:
- Change impact is minimal.
- Consumers understand the source model.
- A single team or a few small teams own all the layers and work together closely.
-
Pure Composition APIs: Sometimes, a Process API just collects data from several System APIs without making any significant changes to them. If the source APIs already return domain-aligned shapes, reusing their models saves time.
-
Thin Experience APIs: If an Experience API doesn’t make many changes, like if it’s just a pass-through layer for analytics dashboards, it might be fine to use the Process API model directly, especially if performance is important.
Mapping vs. Reuse Decision Matrix
| Criteria | Map Upstream Models When | Reuse Upstream Models When |
|---|---|---|
| Layer Separation | Moving from System APIs to Process APIs or from Process APIs to Experience APIs | Models have the same concern or layer boundary |
| Model Ownership | Models are owned outside your context (e.g., SoR models) | Models are owned and versioned within your bounded context |
| Transformation Needed | Models require enrichment, filtering, or business-specific composition | Models are already shaped for its use |
| Consumer-Specific Shaping | Models are tailored to channel needs (e.g., UX or mobile optimization) | Consumer needs are similar |
| Change Risk from Upstream | Changes to the upstream schema are very likely to happen | Stable contracts and predictable changes |
| Governance and Contract Clarity | Each layer defines its own stable contract | A single team manages both sides or internal use |
| Prototyping or Internal Use | Structure should support long-term stability and reuse | Fast-moving use cases where simplicity matters |
Layer Separation
- Map models for moving from System APIs to Process APIs or from Process APIs to Experience APIs.
- Reuse models if they have the same concern or layer boundary.
Model Ownership
- Map models if they are owned outside your context (e.g. SoR models).
- Reuse models if they are owned and versioned within your bounded context.
Transformation Needed
- Map models if they require enrichment, filtering, or business-specific composition.
- Reuse models if they are already shaped for its use.
Consumer-Specific Shaping
- Map models if they are tailored to channel needs (e.g., UX or mobile optimization).
- Reuse models if consumer needs are similar.
Change Risk from Upstream
- Map models if changes to the upstream schema are very likely to happen.
- Reuse models if contracts are stable and changes are predictable.
Governance and Contract Clarity
- Map models if each layer defines its own stable contract.
- Reuse models if a single team manages both sides or internal use.
Prototyping or Internal Use
- Map models if the structure should support long-term stability and reuse.
- Reuse models for fast-moving use cases where simplicity matters.
3. Which layer should enforce user permissions?
Experience API, though others can too
The Experience API layer should mostly enforce user permissions because it is closest to the user and best suited for customizing access based on identity, role, and context.
Depending on how complex and sensitive the logic and data being protected are, both Process and System APIs might include additional permission checks.
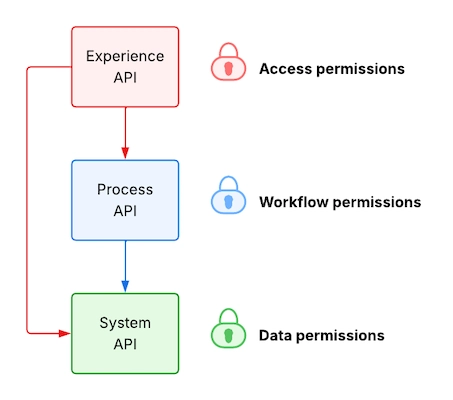
Experience API: Customizes access based on the user’s role, identity, or channel:
- Applies coarse-grained access control (for example, can the user see a certain part?).
- Filters or masks fields (for example, hide private data from people who aren’t admins).
- Uses Attribute-Based Access Control or Role-Based Access Control that works with UI logic.
Optimized for quick, user-centered decision-making.
Process API: Controls who can use business logic:
- Validates roles within workflows (for example, can the user approve big bills?).
- Coordinates policy engines and identity providers.
- Interprets user context and compares it to business rules.
Best for making access decisions based on the situation.
System API: Protects the data boundary:
- Enforces strict data access control, especially in sensitive SoRs like patient records or financial data.
- Acts as the last line of defense in case the checks higher up are bypassed.
- Integrates with Anti-Corruption Layers or backend-level security.
Still, permission control and other security features should be made in a way that keeps APIs reusable.
Security and permission control should be layered and flexible so that protection is enforced without hardcoding behaviors that make it hard to use across channels, teams, or contexts:
- Design APIs to check claims, not callers: Instead of tying logic to specific apps or users, use roles, scopes, or attributes passed in tokens so that any authorized user can interact with them in the right way.
- Keep authorization context external and declarative: Access rules should be centralized in policy engines or gateways so that APIs can stay stateless and reusable.
To support reuse without compromising security, consider the following design practices:
-
Token scopes or claims: Design endpoints to check claims like
read:customerorwrite:invoice, so that they can be used by multiple users but only by those with the right role. - Centralized identity provider: Use a shared identity provider, such as Entra ID, Auth0, Azure AD B2C, etc., to make sure that token issuance is consistent and claims are consistent across layers.
-
Multi-tenant support: Use
tenant_idorcaller_idin tokens to limit access to data safely between business units or domains. - API gateway abstraction: Let the gateway apply high-level policies, while APIs apply more specific, claim-based rules when necessary.
In real life, System APIs are usually made to be agnostic, flexible, and broadly reusable.
Their core responsibility is to expose data from Systems of Record without putting in any business- or consumer-specific logic. This neutrality supports:
- Cross-domain reuse: Different Process or Experience APIs can use them at the same time without any problems.
- Decoupling from consumer context: System APIs don’t make any assumptions about who is calling or why they need the data.
- Scalable security patterns: Access is typically controlled using scopes or claims, rather than hardcoded roles or caller IDs.
However, some domains require additional permission checks, especially where regulatory, privacy, or ethical constraints demand stricter controls:
- Healthcare: Patient data often requires checks for contextual access, consent verification, and audit logging.
- Finance: Account visibility, transactional access, and reporting are tightly controlled based on legal roles and jurisdiction.
- Government or defense systems: Data segmentation, classification, and operator clearance all affect how APIs are made available.
So, yes, agnosticism is the default, but design must be able to handle sensitive data flows. The trick is to add enforcement (through claims, policy engines, or gateways) without hardcoding the logic into the API so that you can still use it in other places.
Access checks may be minimal or not needed at all when:
- Serving data that is low-risk and read-only.
- The entire call chain is trusted and tightly controlled, and the – Experience API enforces all relevant permissions.
- The API is stateless and generic, and the caller is trusted to filter or restrict data.
Even then, always log, monitor, and document the rationale, because trust without visibility is a risky business.
4. Which layer is best for caching and retry policies?
All layers, but for different purposes
Caching and retry policies can technically be used at any layer, but their value and effectiveness depend on the layer’s duties and nature.
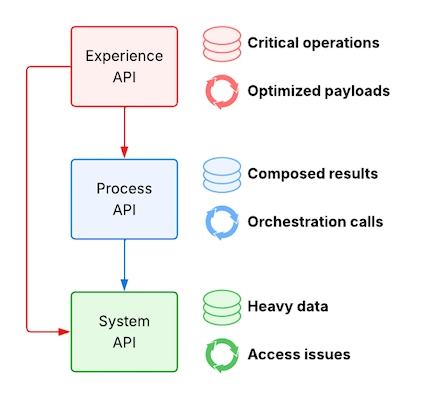
Caching
- System API: Cache responses from slow or read-heavy SoRs (like product catalogs and reference data).
- Process API: Cache composed results if orchestration is expensive and data is stable.
- Experience API: Cache UI-optimized payloads (like homepage data and dropdown lists) for better performance.
Retry Policies
- System API: For temporary problems such as network glitches, timeouts from SoRs or 3rd-party systems.
- Process API: For orchestrated calls to several systems, especially when one might fail from time to time.
- Experience API: For critical operations, but only if the downstream system is idempotent and the user experience is clear to stop duplicate actions or inconsistent state.
Tip: You might want to think about applying retry and caching policies declaratively at the gateway level (like Azure API Management) to keep infrastructure logic out of your code and make centralized management easier.
5. Where is the best place to deal with pagination, filtering, and sorting?
In the System API
The System API is usually the right layer because it is closest to the data. This gives the best performance, especially when you query large datasets directly from Systems of Record that support efficient indexing and querying.
However, there are scenarios in which it makes sense to use these operations in other layers:
- Process API: When you need to combine or aggregate data from several SoRs and no single system can do those tasks on its own. For instance, you could combine customer orders from CRM and ERP systems and then filter them to show only the most valuable ones.
- Experience API: Good for lightweight pagination or consumer-specific filtering when working with small datasets, cached payloads, or for making the UI look different for each user. For instance, filtering a short list of dropdown values or ordering columns in a table based on the user’s preferences.
6. Which layer is suitable for experimentation, like A/B testing and feature flags?
All layers, but for different purposes
Though the types of experiments vary between Experience and Process APIs, they are typically conducted in both. Experimenting with System APIs is dangerous.
Experience APIs are the right place for user-facing or consumer-specific experiments. Here are a few examples:
- UI or personalization experiments: See what improves user satisfaction or interaction. For example, send different field names or formats to web and mobile apps.
- A/B Testing: Measure conversion or engagement. For instance, use different algorithms for product recommendations depending on the user segment.
- Feature Flags and progressive exposure: Introduce new capabilities gradually. Say, give 10% of users access to a new feature.
Because Experience APIs are closest to the user and are made to modify outputs without changing core logic, this experimentation is safe.
Process APIs can be used to experiment with features like business logic, orchestration paths, and data transformation behaviors that are not related to consumer-facing or UI logic:
- A/B Testing of business rules: Compare the effect on conversion or revenue. For example, give 50% of users a 10% discount and give the remaining 50% a loyalty-based discount.
- Alternate orchestration paths: Test reliability or performance of a new backend. Suppose you redirect certain requests from the legacy inventory system to the new one.
- Retry or fallback strategy changes: Evaluate which strategy results in higher uptime or fewer errors. As an example, use exponential backoff for some users and fixed retry for others.
- Caching Strategy Tests: Optimize performance and reduce load on SoRs. Let’s say you try different caching durations for the same operation.
- Rate limiting or throttling logic: Evaluate how well tiered performance limits work. As an example, impose more stringent rate limits on trial accounts while easing them for subscribers.
- Data Aggregation Variants: Check to see if more data leads to better decisions. For instance, add more specific information, such as the average weekly purchase value, to summaries for specific users.
Experimentation with the Process API should concentrate on how it is gathered, processed, and chosen, rather than how data is presented. This aligns well with the API-Led Connectivity pattern, keeping responsibilities clear and allowing experimentation without compromising modularity.
System APIs should not be used for experimentation in most cases because they:
- Are designed to expose and standardize SoR interfaces.
- Must be stable and predictable.
- Serve as the foundation for upstream APIs.
Changing how a System API behaves or what data it returns could break Process or Experience APIs.
However, as with any rule, there may be some exceptions, such as:
- Changes in provider or infrastructure behind the scenes: Improve performance or reliability without changing the expectations of consumers. For example, testing a new database connector or query optimization as long as the contract remains the same.
The following table might help to make the right decision:
| API Layer | Experimentation Type | Acceptable? | Notes |
|---|---|---|---|
| Experience API | A/B tests, user-specific formatting, feature flags | Yes | Safely tailors outputs to consumers |
| Process API | Business rule variation, routing logic, orchestration paths | Yes | Enables testing logic without exposing complexity |
| System API | Interface experiments, changing contract or data shape | No | Risky, may break upper layers |
| System API | Internal performance tweaks, like DB tuning | Maybe | Only if output/contract remains consistent |
Experience API
A/B tests, user-specific formatting, feature flags are ** acceptable**.
An Experience API safely tailors outputs to consumers.
Process API
Business rule variation, routing logic, orchestration paths are acceptable.
A Process API enables testing logic without exposing complexity.
System API
- Interface experiments, changing contract or data shape are not acceptable, because they may break upper layers.
- Internal performance tweaks, like DB tuning may be acceptable, but only if output/contract remains consistent.
7. How to safely expose internal errors?
You can do the following to avoid giving away sensitive backend information while still giving useful feedback at the Experience layer:
- Use a clear error schema, like “E5001: Service unavailable,” to map internal errors to standard codes and messages. This way, you can show what you mean without giving away too much information.
- Keep detailed logs private and share summaries publicly. For example, keep long stack traces and technical context in internal logs or observability tools, and send only error information that is relevant to the user or upstream system.
- Use error translation middleware: Wrap backend responses so that system-specific types of failure (like database timeout) are turned into domain-aware messages (like “Product data not available”).
- Add correlation IDs to responses: Let Experience APIs expose identifiers that developers can use to trace issues without revealing internal architecture.
-
Don’t send exception types or technical identifiers to the consumer: Messages like
NullPointerExceptionorSQLTimeoutshould stay behind the scenes.
Not only does this protect internal systems, but it also makes error handling more consistent and user-friendly across layers.
8. Why not provide the business logic in a package instead of creating a Process API? It could speed up response time and reduce latency.
Both approaches have their pros and cons
The right choice depends on what your system needs: Do you need speed and simplicity, or flexibility and reuse?
A package might be best if performance is the most important thing and your logic is fixed or very specific. A Process API is a better choice for the long term if your logic covers more than one service and changes over time.
Putting business logic into libraries like NuGet, Maven, and NPM has a lot of benefits, especially for performance-critical apps. Here are some of the main benefits:
- Performance and low latency: Package code runs right in the application’s process, so there are no network or service overheads. It’s perfect for logic that needs to respond right away, like rendering a user interface, checking input, or processing on the client side. For instance, a high-throughput trading platform embeds its risk-scoring logic in a package instead of exposing it through an API. This guarantees that transactions are completed in minimal time during peak loads.
- Easy testing and debugging: Developers can write unit tests for packaged logic without having to mock network calls or infrastructure. Also, running things locally makes behavior more predictable and easier to follow during development.
- Development simplicity: There is no need to set up services or manage infrastructure. You can simply import the package and use the logic. It works best when development speed is more important than design. It’s also very helpful for early-stage projects or MVPs. It’s a quick way to add features to many services without having to build APIs.
- Offline capabilities: Packages don’t need to be connected to the network, so they’re great for apps that work in low-bandwidth environments or offline modes. Think about mobile apps for field service that need to work in places with no internet access.
- Strong encapsulation: Packaged logic can enforce strict modular boundaries, such as strong typing and self-contained units. It makes things clearer, easier to document, and simpler to move between projects. You can provide your functionalities to desktop apps, microservices, or CLI tools - all from the same codebase.
However, using packages might also cause duplication and limit visibility across systems.
Here is how Process APIs address the drawbacks of packaged logic:
- Centralized control: When logic is spread out through libraries, each consumer has to take care of their own copy. You have to recompile and redeploy every app to update business rules. A Process API makes orchestration more centralized, so updates happen right away and are the same for all consumers.
- Internal bug fixes: When an issue or bug is found in the system, it can be resolved within the API. The consumers don’t need to be redeployed or recompiled. In contrast, packaged logic requires coordination with the teams that own the consumer code, as any bug fix involves updating the package, changing the consumer code, and redeploying it. Upstream consumers may also need to be updated as a result, which could have a cascading effect that increases deployment effort and complexity.
- Runtime governance and monitoring: Process APIs live at the service boundary, so you can use policies like rate limiting, quotas, logging, and auditing. Local packages run in the app, which is great for speed but not for operations.
- Faster innovation: With a Process API, you can implement experimentation like A/B testing on the business logic level. Packages need coordinated deployments, which slows down experimentation and responsiveness.
Tradeoff Summary
| Approach | Pros | Cons |
|---|---|---|
| Packages | Fast, low-latency, easy unit testing | Hard to manage changes, no runtime control |
| Process API | Centralized, governed, dynamic orchestration | Higher latency, network overhead |
Packages
- Pros: Fast, low-latency, easy unit testing.
- Cons: Hard to manage changes, no runtime control.
Process API
- Pros: Centralized, governed, dynamic orchestration.
- Cons: Higher latency, network overhead.

