Master RAG Evaluation with RAGAS
In recent years, Retrieval-Augmented Generation (RAG) has become one of the go-to architectures for enterprises building AI assistants, knowledge search systems, and domain-specific agents. As companies ingest more documents, RAG systems grow complex — with custom retrievers, vector stores, and prompt engineering. To ensure the RAG pipeline performs well and returns results without hallucinations, the open-source framework Ragas (Retrieval-Augmented Generation Assessment Suite) is widely used to evaluate RAG pipelines.
**
What is Ragas?
**
Ragas is an open-source evaluation framework designed specifically for RAG pipelines. Instead of evaluating the LLM output in isolation, Ragas assesses the full loop:
user question → Retrieved context → Generated answer from LLM → Final Answer.
Below are the core metrics used for evaluating the full loop. In 2025, the four metrics are widely used to evaluate the output:
Context Precision, Context Recall, Faithfulness, and Answer Relevancy. These four cover >95% of real-world evaluation needs without requiring hard-to-get ground-truth answers.
Note: Older tutorials sometimes mention metrics like answer_correctness or context_relevance, but they are rarely used in modern pipelines .
Below are 4 Core RAGAS Metrics :
1. Context Recall
“Out of everything that should have been retrieved to answer the question correctly, how much did we actually manage to retrieve?”
An LLM extracts relevant statements from the ground-truth answer and checks if they appear in the retrieved context (no need for full corpus labels).
Perfect Score: 1.0
Common real-world range: 0.70–0.95
- Score = 1.0 → We retrieved all the relevant pieces of information.
- Score = 0.6 → We missed 40% of the truly relevant context.
2. Context Precision
“Of all the chunks we brought back, how many are truly useful vs. how many are just noise or irrelevant?”
Verifies the relevance of each retrieved chunk to the question using an LLM judge.
Perfect Score: 1.0
Common real-world range: 0.85–0.98
- Score = 1.0 → Everything we retrieved is relevant (zero noise).
- Score = 0.8 → 20% of the retrieved chunks are irrelevant or distracting.
- Score = 0.4 → Only 40% of what we retrieved is actually helpful; the other 60% is junk.
3. Faithfulness
“Does the model make stuff up, or is every single claim backed by the retrieved chunks?”
Breaks the answer into atomic claims and verifies each one against the context (fine-grained hallucination check; replaced the older “groundedness”).
Perfect Score: 1.0
Common real-world range: 0.90–1.00
- Score = 1.0 for Faithfulness → 100% faithful: no hallucinated claims.
- Score = 0.85 → 15% of the claims are not supported → some hallucination.
4. Answer Relevancy
“Does the answer actually answer what was asked, or is it off-topic, incomplete?”
An LLM judge evaluates completeness, focus, and lack of tangents.
Perfect Score: 1.0
Common real-world range: 0.88–0.99
- Score = 1.0 → Fully relevant: answers the question completely and stays focused.
- Score = 0.8 → Mostly relevant but slightly incomplete or contains minor irrelevant parts.
- Score = 0.3 → Largely irrelevant, evasive, or misses the main point of the question.
from datasets import Dataset # Hugging Face datasets
from ragas import evaluate
from ragas.metrics import (
context_precision,
context_recall,
answer_relevancy,
faithfulness,
)
data = {
"question": ["What is RAG?"],
"answer": ["RAG combines retrieval and generation for better AI responses."],
"contexts": [["Retrieval-Augmented Generation (RAG) is a technique..."]],
"ground_truth": ["RAG enhances LLMs by fetching external knowledge."], # Optional
}
test_dataset = Dataset.from_dict(data)
result = evaluate(
dataset=test_dataset, # Or 'data=' in some older versions
metrics=[context_precision, context_recall, answer_relevancy, faithfulness],
)
print(result)
# Output example: {'context_precision': 0.92, 'context_recall': 0.85, 'faithfulness': 0.98, 'answer_relevancy': 0.94}
The Real Use Case:
Comparing Versions of Your RAG Pipeline: The true power of Ragas emerges when you use it to compare versions of your RAG pipeline. A RAG system has two major components:
Retrieval: Pulling the right documents.
Generation: Producing a correct, grounded answer.
Ragas evaluates both.
- Evaluate Retrieval Quality: RAGAS checks whether your retriever is bringing back the right information. It answers questions like:
Are we retrieving relevant chunks?
Are we retrieving too much noise or irrelevant text?
Metrics that help:
- Context Recall: Did we retrieve what we should retrieve?
- Context Precision: What proportion of what we retrieved was relevant?
- Evaluate Generation Quality: Even if retrieval is perfect, the LLM may hallucinate, skip details, or misinterpret the context. Ragas checks the quality of the generated answer. It answers:
Is the answer factually correct?
Did the model stay grounded in the retrieved context?
Metrics that help:
- Faithfulness: Checks for hallucinations (no unsupported claims).
- Answer Relevancy: Ensures the answer is on-topic and complete.
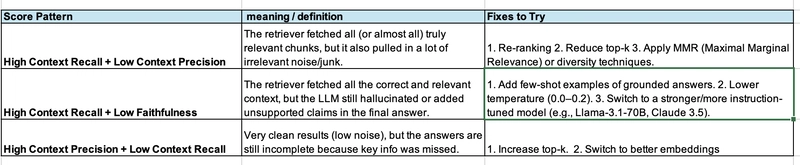
Use the below score combinations to understand the issue and iterate on the RAG pipeline: