Improving Network Performance with Custom eBPF-based Schedulers
Author: Ian Chen
If you’re interested, feel free to ⭐ the repo (aiming for CNCF Landscape recognition — the maintainers are happy to accept the project, but it needs at least 300 ⭐), try it out, share feedback, or even contribute together!
Linux Kernel has supported sched_ext since v6.12, which allows users to define custom CPU schedulers through eBPF programs. This feature enables developers to create more flexible and efficient scheduling strategies to meet specific performance requirements.
The author was deeply inspired by the scx project and, referring to the concept of scx_rustland, implemented a framework scx_goland_core that allows developers to write custom schedulers using the Go language.
Potential Integration of scx with 5G Domain
Regarding the combination of 5G and scx, there has been some discussion [1] [2] [3]. However, considering the characteristics of modern Cloud-Native Apps (5G Core Network), there are currently no related cases exploring how scx operates on cloud-native architectures.
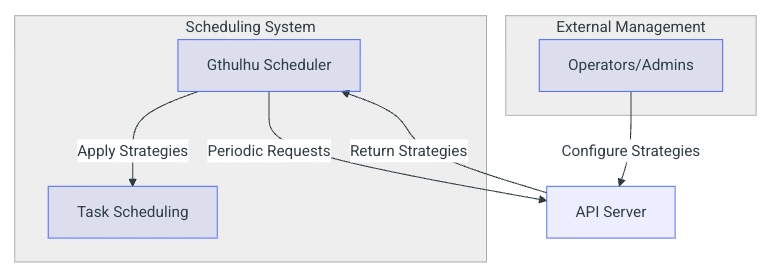
Figure 1: API Architecture
In response, the author proposes an initial idea and developed a custom scheduler Gthulhu based on the scx_goland_core framework that can run in cloud-native environments. It can be deployed in Kubernetes clusters and manage scheduling policies for numerous nodes in the cluster through deployment.
We can issue scheduling policies to the Gthulhu API server through RESTful APIs, allowing the API server to identify workloads that need adjustment. Meanwhile, Gthulhu periodically sends heartbeat messages to the API server and updates scheduling policies when necessary.
For detailed information about Gthulhu, please refer to Gthulhu Docs.
First Trial: Observing Data Plane Performance Differences After Loading Gthulhu
In this experiment, the author’s machine runs on Ubuntu 24.04 LTS with Linux Kernel 6.12. The experiment aims to observe the impact of Gthulhu on data plane performance after loading.
The test environment is as follows:
- VM1 (Ubuntu 24.04 LTS, Linux Kernel 6.12)
- Deploy free5GC v4.0.1
- VM2 (Ubuntu 20.04 LTS, Linux Kernel 5.4.0)
- Deploy UERANSIM
After establishing the PDU Session, the author used the ping tool to test the UPF N6 interface and observed latency changes before and after loading Gthulhu.
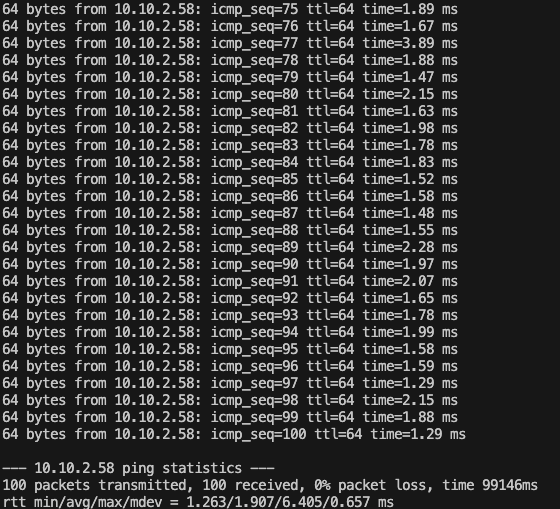
Before loading, Linux’s default scheduler was EEVDF, with RTT parameters as follows:
- rtt min = 1.263 ms
- rtt avg = 1.907 ms
- rtt max = 6.405 ms
- rtt mdev = 0.657 ms
After loading Gthulhu, the RTT parameters changed as follows:
- rtt min = 1.222 ms
- rtt avg = 1.864 ms
- rtt max = 3.771 ms
- rtt mdev = 0.433 ms
From these results, we can see that after loading Gthulhu, both the average and maximum RTT values decreased, indicating that Gthulhu indeed helps reduce latency in data plane scheduling.
Optimizing GTP5G Scheduling
Based on the previous experimental results, we can see that without any scheduler adjustments, Gthulhu effectively reduces RTT performance. So, can we leverage knowledge of the network subsystem combined with Gthulhu to further optimize GTP5G?
[!Note]
Experimental environment:
- 5GC on kubernetes
- N3/N6 use Multus CNI to create macvlan interfaces (N6 bound to enp7s0, N3 interface bound to dummy interface)
Observing Which CPU Handles Downlink Processing
$ grep enp7s0 /proc/interrupts
159: 116096 131508 763166 532207 4697697 3924514 24589811 5660340 29315073 11862910 25971964 8494127 1935719 2420802 5149765 948266 6835920 2126158 1825640 1044404 IR-PCI-MSIX-0000:07:00.0 0-edge enp7s0
From the command above, we can see that enp7s0 corresponds to IRQ 159. Next, using cat /proc/irq/${IRQ}/smp_affinity_list, we can determine which CPU IRQ 159 is bound to:
$ cat /proc/irq/159/smp_affinity_list
11
When enp7s0 receives packets from the Data Network, it forwards them to the n6 interface corresponding to the UPF Container, and the N6 interface forwards downlink packets to the virtual interface gtp5g.
Therefore, the CPU handling gtp5g downlink traffic should be CPU 11, which can be verified through an eBPF program.
In the author’s previous article Debug gtp5g kernel module using stacktrace and eBPF, the possibility of using eBPF to trace kernel modules was explored. By examining the gtp5g source code, we can see that downlink packets eventually enter gtp5g_xmit_skb_ipv4. Using sudo cat /sys/kernel/tracing/available_filter_functions | grep gtp5g also confirms that this function is in the available_filter_functions list.
SEC("fentry/gtp5g_xmit_skb_ipv4")
int BPF_PROG(capture_skb, struct sk_buff *skb, struct gtp5g_pktinfo *pktinfo)
{
__u64 pid_tgid = bpf_get_current_pid_tgid();
__u32 pid = pid_tgid & 0xFFFFFFFF;
__u32 tgid = pid_tgid >> 32;
__u32 cpu = bpf_get_smp_processor_id();
bpf_printk("gtp5g_xmit_skb_ipv4: PID=%u, TGID=%u, CPU=%u", pid, tgid, cpu);
return 0;
}
After loading the above eBPF program into the kernel, when using UERANSIM to establish a PDU Session and send ICMP packets to 8.8.8.8, we can observe the eBPF program output:
gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156182.987076: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156183.987343: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156184.986858: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156185.987004: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156186.987574: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156187.987330: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156188.987722: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156189.988054: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156190.988038: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
kubelite-3377186 [011] b.s21 6156191.987614: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=3377186, TGID=3376931, CPU=11
<idle>-0 [011] b.s31 6156192.987963: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156193.987763: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
<idle>-0 [011] b.s31 6156194.988095: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=11
From the eBPF program output, we can confirm that gtp5g’s downlink traffic is indeed handled by CPU 11, consistent with our previous speculation.
When I use echo "12" | sudo tee /proc/irq/159/smp_affinity_list to modify the CPU bound to IRQ 159, the eBPF program output immediately changes:
gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156445.013125: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156446.012413: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156447.012498: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156448.013280: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156449.012909: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156450.013119: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
<idle>-0 [012] b.s31 6156451.013496: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=0, TGID=0, CPU=12
Note:
The CPU bound to IRQ may be dynamically updated by irqbalance. It’s recommended to use$ sudo systemctl stop irqbalanceto temporarily disable irqbalance.
That said, even with irqbalance disabled, the eBPF program output may still show unexpected situations.
When I changed the ICMP target from an external IP to the UPF container’s own N6 interface IP, the eBPF program output was as follows:
nr-gnb-168420 [016] b.s41 6158463.012636: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=16
nr-gnb-168420 [016] b.s41 6158464.012282: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=16
nr-gnb-168420 [017] b.s41 6158465.012408: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=17
nr-gnb-168420 [017] b.s41 6158466.012551: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=17
nr-gnb-168420 [016] b.s41 6158467.012401: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=16
nr-gnb-168420 [006] b.s41 6158468.012565: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158469.012700: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158470.012549: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158471.012763: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
nr-gnb-168420 [006] b.s41 6158472.012862: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=168420, TGID=168410, CPU=6
Basically, the CPU executing gtp5g_xmit_skb_ipv4 will always be the CPU that the scheduler allocates to the nr-gnb process. The reason is simple: packets sent to the N6 interface are processed completely within the container and don’t pass through the enp7s0 interface, so packets from UERANSIM all the way to N6 and back are handled within the same context.
Understanding the Linux kernel’s packet processing behavior, we can experiment to see how UERANSIM performs when sending ICMP echo requests to the UPF N6 IP through uesimtun0 under system full load conditions.
Gthulhu Configuration Settings
In this experiment, the configuration settings are fixed as follows:
# Gthulhu Scheduler Configuration
# This configuration file allows you to adjust scheduler parameters before eBPF program loading
scheduler:
# Default time slice in nanoseconds (default: 5000000 = 5ms)
slice_ns_default: 2000000
# Minimum time slice in nanoseconds (default: 500000 = 0.5ms)
slice_ns_min: 500000
api:
enabled: false
url: http://127.0.0.1:8080
interval: 5
debug: false
early_processing: false
builtin_idle: false
Using stress-ng to Generate Load
$ stress-ng -c 20 --timeout 60s --metrics-brief
Testing with ping
Since the Gthulhu scheduler borrows from the design of scx_rustland, we use scx_rustland as the control group in this experiment:
/UERANSIM # taskset -c 5 ping 10.10.2.60 -I uesimtun0 -c 10
PING 10.10.2.60 (10.10.2.60): 56 data bytes
64 bytes from 10.10.2.60: seq=0 ttl=64 time=75.589 ms
64 bytes from 10.10.2.60: seq=1 ttl=64 time=75.917 ms
64 bytes from 10.10.2.60: seq=2 ttl=64 time=63.919 ms
64 bytes from 10.10.2.60: seq=3 ttl=64 time=71.934 ms
64 bytes from 10.10.2.60: seq=4 ttl=64 time=72.005 ms
64 bytes from 10.10.2.60: seq=5 ttl=64 time=64.108 ms
64 bytes from 10.10.2.60: seq=6 ttl=64 time=83.945 ms
64 bytes from 10.10.2.60: seq=7 ttl=64 time=100.525 ms
64 bytes from 10.10.2.60: seq=8 ttl=64 time=59.987 ms
64 bytes from 10.10.2.60: seq=9 ttl=64 time=63.940 ms
--- 10.10.2.60 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 59.987/73.186/100.525 ms
We can observe that when every CPU in the system is fully loaded, scx_rustland performs very poorly in packet processing efficiency. This problem also exists with the Gthulhu scheduler:
/UERANSIM # taskset -c 5 ping 10.10.2.60 -I uesimtun0 -c 10
PING 10.10.2.60 (10.10.2.60): 56 data bytes
64 bytes from 10.10.2.60: seq=0 ttl=64 time=22.085 ms
64 bytes from 10.10.2.60: seq=1 ttl=64 time=59.904 ms
64 bytes from 10.10.2.60: seq=2 ttl=64 time=96.299 ms
64 bytes from 10.10.2.60: seq=3 ttl=64 time=20.349 ms
64 bytes from 10.10.2.60: seq=4 ttl=64 time=71.244 ms
64 bytes from 10.10.2.60: seq=5 ttl=64 time=28.001 ms
64 bytes from 10.10.2.60: seq=6 ttl=64 time=74.964 ms
64 bytes from 10.10.2.60: seq=7 ttl=64 time=59.977 ms
64 bytes from 10.10.2.60: seq=8 ttl=64 time=32.617 ms
64 bytes from 10.10.2.60: seq=9 ttl=64 time=90.945 ms
--- 10.10.2.60 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 20.349/55.638/96.299 ms
Next, let’s try the following approach to see if we can reduce round-trip-time:
- Assign a specific CPU (using CPU 5 here) to UERANSIM and the
icmptool - If other tasks are assigned to CPU 5, randomly assign them to other CPUs
Related changes can be found in:
// ...
log.Println("scheduler started")
+ var specialPid int32 = 168420 // Special case for PID 168420
+ var specialPidCpu int32 = 5
for true {
select {
case <-ctx.Done():
log.Println("context done, exiting scheduler loop")
return
default:
}
sched.DrainQueuedTask(bpfModule)
t = sched.GetTaskFromPool()
if t == nil {
bpfModule.BlockTilReadyForDequeue(ctx)
} else if t.Pid != -1 {
task = core.NewDispatchedTask(t)
err, cpu = bpfModule.SelectCPU(t)
if err != nil {
log.Printf("SelectCPU failed: %v", err)
}
+ if t.Pid == specialPid {
+ if specialPidCpu == -1 && cpu != core.RL_CPU_ANY {
+ specialPidCpu = cpu
+ } else {
+ cpu = specialPidCpu
+ }
+ } else {
+ if cpu == core.RL_CPU_ANY {
+ // ramdom select cpu 0-19
+ cpu = int32(rand.Intn(20))
+ }
+ if specialPidCpu == cpu {
+ if (cpu & 1) == 1 {
+ cpu = cpu - 1
+ } else {
+ cpu = cpu + 1
+ }
+ }
+ }
// Evaluate used task time slice.
nrWaiting := core.GetNrQueued() + core.GetNrScheduled() + 1
task.Vtime = t.Vtime
Special pid 168420 was observed through the eBPF program as the process id responsible for executing gtp5g_xmit_skb_ipv4():
nr-gnb-770208 [005] b.s41 6233538.456200: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233711.301750: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233712.346565: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233713.312931: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233714.314609: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233715.340537: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233716.337300: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233717.389852: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233718.387986: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] b.s41 6233719.368526: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
nr-gnb-770208 [005] bNs41 6233720.396073: bpf_trace_printk: gtp5g_xmit_skb_ipv4: PID=770208, TGID=770198, CPU=5
After completing the modifications, let’s try running Gthulhu again and test once more:
/UERANSIM # taskset -c 5 ping 10.10.2.60 -I uesimtun0 -c 10
PING 10.10.2.60 (10.10.2.60): 56 data bytes
64 bytes from 10.10.2.60: seq=0 ttl=64 time=0.767 ms
64 bytes from 10.10.2.60: seq=1 ttl=64 time=1.150 ms
64 bytes from 10.10.2.60: seq=2 ttl=64 time=1.120 ms
64 bytes from 10.10.2.60: seq=3 ttl=64 time=0.968 ms
64 bytes from 10.10.2.60: seq=4 ttl=64 time=1.002 ms
64 bytes from 10.10.2.60: seq=5 ttl=64 time=0.601 ms
64 bytes from 10.10.2.60: seq=6 ttl=64 time=1.132 ms
64 bytes from 10.10.2.60: seq=7 ttl=64 time=0.833 ms
64 bytes from 10.10.2.60: seq=8 ttl=64 time=0.666 ms
64 bytes from 10.10.2.60: seq=9 ttl=64 time=0.795 ms
--- 10.10.2.60 ping statistics ---
10 packets transmitted, 10 packets received, 0% packet loss
round-trip min/avg/max = 0.601/0.903/1.150 ms
From the results, the modified Gthulhu scheduler enables the UPF to process packets from UERANSIM in a short time under high load conditions. This performance is consistent with our expectations.
Reducing RTT through Custom Configuration
In the previous experiments, we allocated dedicated CPUs for specific processes, which indeed improved RTT performance under high load conditions. However, this approach is not universal, as each system’s load conditions and workloads may differ.
Therefore, Gthulhu has developed a set of custom configuration settings that allow users to adjust scheduling strategies according to their needs. For the project source code, please refer to Gthulhu/api.
{
"server": {
"port": ":8080",
"read_timeout": 15,
"write_timeout": 15,
"idle_timeout": 60
},
"logging": {
"level": "info",
"format": "text"
},
"jwt": {
"private_key_path": "./config/jwt_private_key.key",
"token_duration": 24
},
"strategies": {
"default": [
{
"priority": true,
"execution_time": 20000,
"selectors": [
{
"key": "app",
"value": "ueransim-macvlan"
}
],
"command_regex": "nr-gnb|nr-ue|ping"
}
]
}
}
Through the above JSON file, the API server can identify corresponding processes and update these processes’ scheduling strategies to Gthulhu.
If a task has "priority": true, the task itself can preempt other non-"priority": true tasks, significantly reducing the time from runnable to running state.
In the free5GC integration case, reducing ueransim’s scheduling delay means that the UPF can process packets from the RAN more quickly, thereby reducing overall RTT.
The above video demonstrates how Gthulhu significantly reduces RTT performance through custom scheduling strategies under high load conditions.
Additionally, Gthulhu also supports a simple WEB GUI, allowing users to manage and monitor
Conclusion
5G introduces the concept of network slicing, expecting to provide different service qualities by dividing physical networks into multiple virtual networks. With custom schedulers like Gthulhu, we can more flexibly manage and optimize the performance of these virtual networks, deploy UPFs with different business requirements on different nodes, and adjust scheduling strategies according to actual needs.
About the Author
Ian Chen is a developer passionate about open source technology, focusing on research in 5G and cloud-native architectures. He initiated the Gthulhu project and is also a major contributor to free5GC, dedicated to promoting and implementing open source solutions for 5G networks.
