Virtual Studio AI: The End of the Photoshoot
What I Built
Traditional photoshoots are the biggest bottleneck for modern brands. They are expensive, slow, and logistically complex. I built Virtual Studio AI to solve this problem.
Virtual Studio AI is an all-in-one, AI-powered content platform that completely eliminates the need for physical photoshoots. It empowers brands, marketers, and designers to generate an infinite variety of world-class, commercially-ready visuals—on-model, on-product, and on-demand—at a fraction of the cost and time.
The applet is organized into four powerful, interconnected studios:
- 👕 Apparel Studio: The core of the platform. Users upload their model (or create one with AI) and their apparel. The AI intelligently merges them into a single, photorealistic image with incredible control over lighting, pose, and style.
- 📦 Product Studio: Elevates standard product shots into stunning lifestyle scenes. It features AI background removal, an interactive staging canvas to visually compose shots, and an AI Prop Assistant.
- 🎨 Design Studio: The ultimate mockup engine. It features a live, interactive preview that shows your design on a garment in real-time as you adjust placement, scale, and realism settings.
- ✨ Reimagine Studio: A powerful photo-remixing tool. Users can take any existing photo and swap the model or the background using text prompts or reference images, preserving the original pose and outfit.
Demo
Deployed Applet Link:
[Link to your deployed applet on Cloud Run] – Note: The applet is not currently deployed. The last deployment was during the Kaggle NanoBanana Hackathon, which resulted in a RS :5,000 API usage bill—so I’ve held off on redeploying for now.
Google Ai studio Link:
https://ai.studio/apps/drive/1b6Dvez6gA_CON_3O9PNnhbdjN5x-myz4
Screenshots & Video:
(It is highly recommended to include a short screen recording here to best showcase the app’s dynamic and interactive nature.)
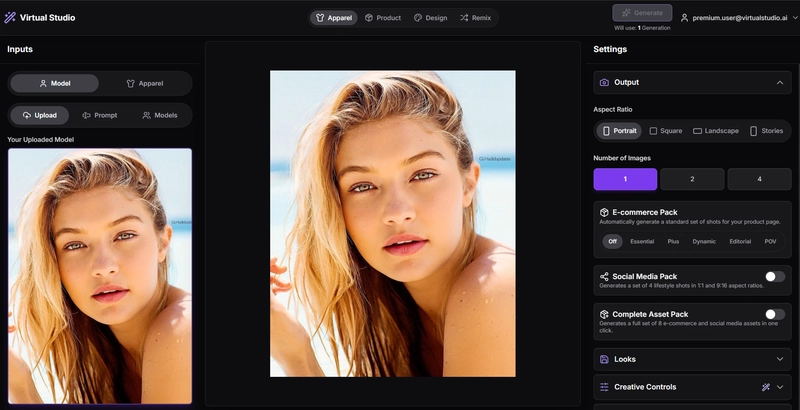
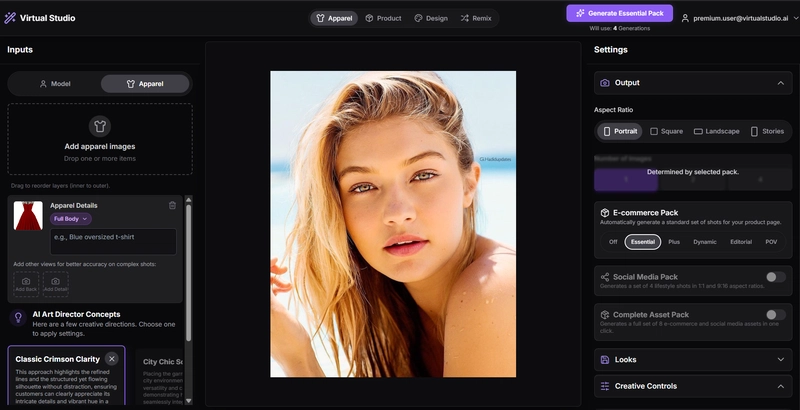
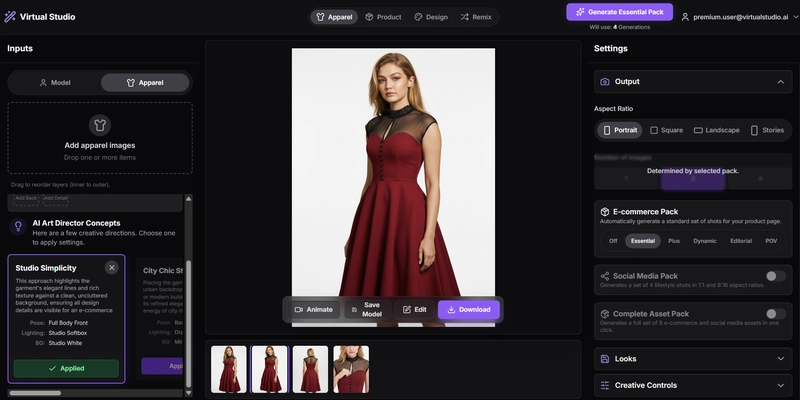
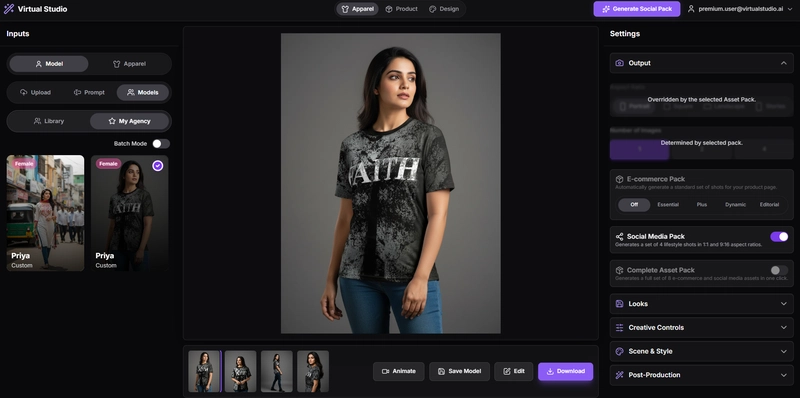
How I Used Google AI Studio
Google AI Studio and the Gemini family of models are the engine behind this entire application. I used a “right tool for the right job” approach, leveraging the specific strengths of different models to build a cohesive and powerful user experience.
-
gemini-2.5-flash-image-preview: This was the workhorse for all complex image-to-image and text-and-image-to-image tasks. Its ability to take multiple image inputs (model, apparel, mask, style reference) and a detailed text prompt made it the perfect choice for the core Virtual Try-On, the Generative Edit (inpainting) feature, AI background removal, and the entire Reimagine Studio. -
gemini-2.5-flash: This model served as the “brains” for visual understanding and structured data output. I used it for the AI Art Director (analyzing an apparel image to suggest full photoshoot concepts), the AI Stylist (determining layering order), the AI Prop Assistant, and for analyzing user-uploaded models to extract descriptive details. The ability to specify a JSON response schema was critical for this. -
imagen-4.0-generate-001: For pure, high-fidelity image generation from a text prompt, I used Imagen. This powered the AI Graphic Designer in the Design Studio (creating logos and graphics from scratch) and the AI Model Prompter (creating new, photorealistic models for the user’s private “agency”). Its excellence in rendering text and photorealism was essential here. -
veo-2.0-generate-001: To add another layer of value, I integrated Veo to power the Image-to-Video animation feature. This allows users to take their final static image and generate a short, engaging video clip for social media or product pages.
The entire application was built within Google AI Studio and is deployed on Cloud Run, as per the challenge requirements.
Multimodal Features
Multimodality isn’t just a feature of Virtual Studio AI; it’s the fundamental principle that makes the entire workflow possible. Here’s how it enhances the user experience:
-
The Core Virtual Photoshoot (Image + Text -> Image): The user provides multiple, distinct visual inputs (a model’s face, a flat garment photo) and combines them with a highly detailed text prompt that describes the pose, lighting, and scene. Gemini’s ability to understand and synthesize these disparate inputs into a single, cohesive, photorealistic image is the core magic of the app. It moves beyond simple text-to-image into a true “virtual art direction” experience.
-
AI Art Director (Image -> Structured Text): This feature is a prime example of multimodal understanding. The applet sends an apparel image to Gemini and asks it to “think like an art director.” The model analyzes the visual style of the garment and returns structured JSON data containing complete, actionable photoshoot concepts. This bridges the creative gap for users and turns a visual asset into a set of creative recipes.
-
Generative-First Asset Creation (Text -> Image): With the Imagen-powered AI Graphic Designer and Model Prompter, the user is no longer limited by the assets they already have. They can describe a design or a model in natural language and have a production-ready visual asset generated directly within their workflow. This is a massive UX improvement over needing to use separate tools.
-
Generative Edit (Image + Mask + Text -> Image): This gives users fine-grained control that feels intuitive. Instead of complex photo editing tools, the user simply “paints” an area of the image (creating a mask) and describes the change they want. This combination of visual (the mask) and linguistic (the prompt) input makes complex edits accessible to everyone.
-
Image-to-Video Animation (Image + Text -> Video): This feature directly addresses a major need for brands: creating engaging motion content. By taking a final, perfected still image and animating it based on a simple text instruction (e.g., “gentle sway”), the applet transforms one multimodal asset into another, adding significant value for social media and marketing.







