Guess My Drawing: Can Gemini Read Your Mind in One Line?
This is a submission for the Google AI Studio Multimodal Challenge
What I Built
I built a game called Guess My Drawing and it does exactly what it sounds like – except the AI is watching.
Here’s how it works:
- First, Gemini generates 4 original images for you. All square, all simple enough to draw (in theory)..
- You pick one and draw it on the canvas, but here’s the twist: you only get one line.
- You have 10 seconds and the timer will judge you.
- Then Gemini tries to guess which image you picked – and explains why.
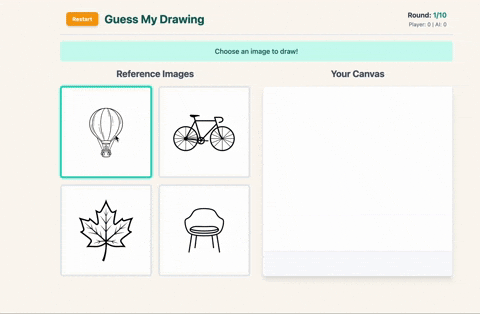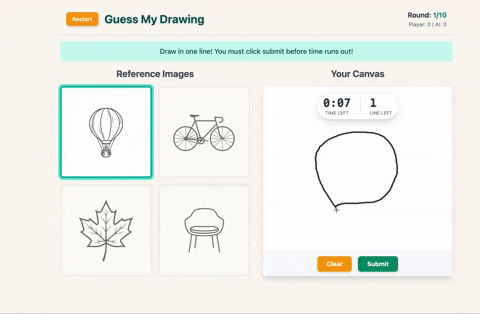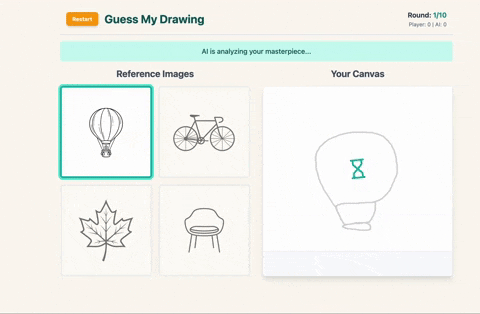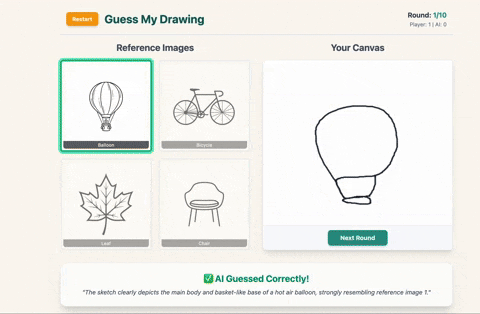
✅ If it guesses correctly, you score a point.
❌ If it guesses wrong or can’t figure out what you drew (because the timer ran out or your sketch resembled existential spaghetti), the AI scores instead.
It’s you versus the model for 10 rounds.
And just when you think you’ve got it down, the images get harder. Every 3 rounds the prompts get more complex and abstract.
(You think drawing a banana is hard? Try drawing “an anxious goblin in baroque style” in one stroke.)
Demo
Live game link: https://guess-my-drawing-ai-467116247258.us-west1.run.app
Github link: https://github.com/olgazju/guess_my_drawing_ai
I recorded 3 short demo runs:
- I win (AI guessed correctly)
- AI wins (AI guessed uncorrectly)
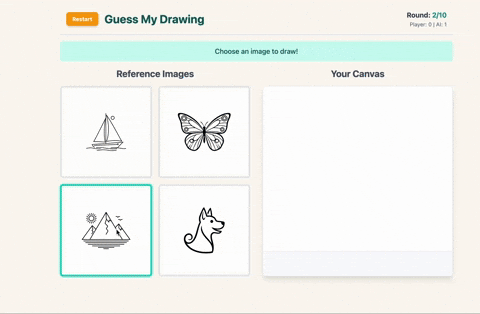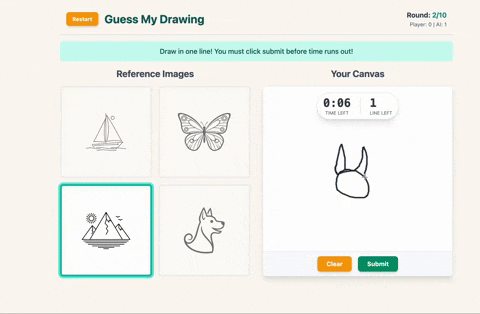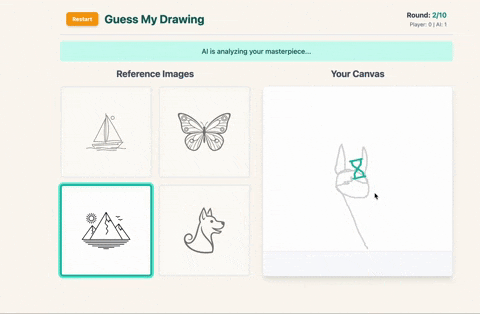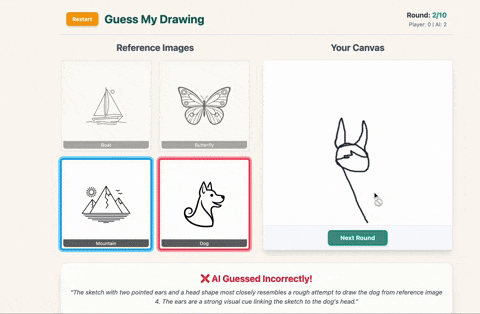
- AI gives up (my masterpiece was too avant-garde, apparently)
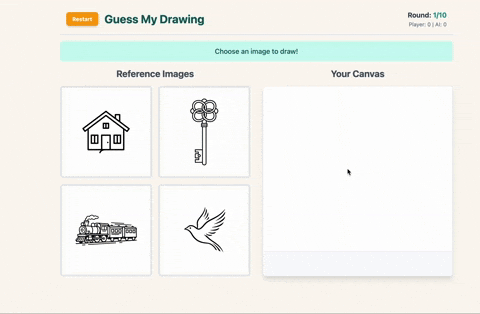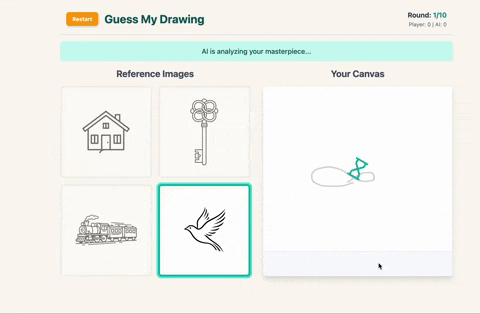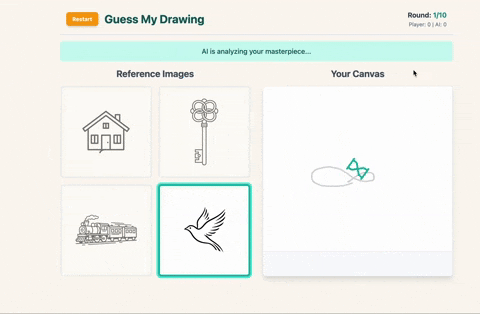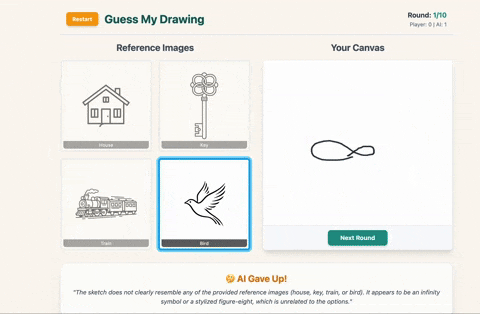
How I Used Google AI Studio
The entire game was developed directly in Google AI Studio, including both the image generation and sketch analysis logic. I used the built-in code editor to handle everything, from prompt design to response parsing, without needing to switch to any external tools.
At the start of each round the app sends 4 short prompts like
“A smiling dinosaur wearing sunglasses, Pixar style” to the gemini-2.5-flash-image-preview model via generateContent. The model returns four base64‑encoded PNGs, which are shown to the player as selectable options.
After the player draws their selected image in a single line, the sketch is sent back to Gemini with a follow-up prompt that asks it to identify which of the four images the drawing most closely resembles and explain why. The model responds with a guessed index and a short explanation, which are then shown in-game.
Multimodal Features
This project uses two core multimodal capabilities from Gemini:
-
Text-to-Image
The game uses the gemini-2.5-flash-image-preview model to generate four images at the beginning of each round. Each image is created from a short, structured prompt and returned as a base64-encoded PNG. The images are displayed in a grid for the player to choose from. -
Image-to-Text
After the player draws their chosen image, the sketch is converted to base64 and sent to the model with a prompt asking it to identify which of the four options the sketch most closely resembles. The response includes the guessed index and a short explanation, which are displayed as part of the round results.
This loop – from prompt to image to sketch to AI guess – creates a fast, interactive rhythm that makes the game feel alive. You’re not just clicking buttons or watching the AI perform; you’re actively trying to communicate with it using a single line. Sometimes it gets you immediately. Sometimes it completely misreads your masterpiece. But that unpredictability is part of what makes the experience fun – it feels like a conversation, just in pictures.
Want to play?
Come draw something terrible. I promise Gemini won’t judge. Much.