Lightweight ETL with AWS Lambda, DuckDB, and delta-rs
Introduction
I’m Aki, an AWS Community Builder (@jitepengin).
In my previous articles, I’ve focused mainly on Apache Iceberg:
https://dev.to/aws-builders/lightweight-etl-with-aws-lambda-duckdb-and-pyiceberg-1l5p
https://dev.to/aws-builders/build-a-lightweight-serverless-etl-pipeline-to-iceberg-tables-with-aws-lambda-athena-661
https://dev.to/aws-builders/lightweight-etl-with-aws-glue-python-shell-duckdb-and-pyiceberg-153l
While Iceberg is quickly becoming the de facto standard for Open Table Formats (OTF), Delta Lake is still the first choice when using Databricks.
In this article, I’ll walk through an approach to reduce costs by offloading preprocessing to lightweight ETL before handing the workload over to Databricks.
The idea is to build the Bronze layer with Lambda-based ETL, while leveraging Databricks for Silver and Gold layers (aggregation and analytics).
What is Delta Lake?
Delta Lake is an ACID-compliant data lake format built on top of Apache Parquet.
Key features:
- ACID transactions: Ensures consistency even with concurrent writes.
- Time travel: Query historical versions of data.
- Schema evolution: Easily add or modify columns.
- Performance optimizations: Z-Order clustering and data skipping.
It’s the primary storage format on Databricks and widely used for ETL, BI, and ML pipelines.
Architecture used in this article
Here’s the architecture we’ll discuss:
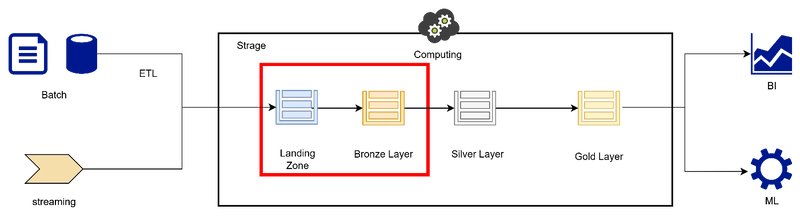
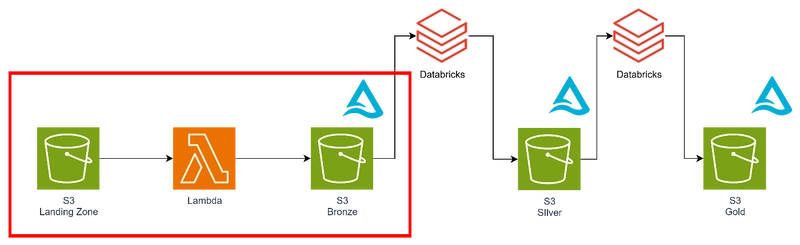
The preprocessing stage (Landing → Bronze) is handled by Lambda with Delta format output.
The Bronze → Silver and Silver → Gold stages, which require heavier compute, are handled by Databricks.
Focus of this article: the red box (Landing → Bronze).
- Landing → Bronze: Lightweight ETL with Lambda (Delta format)
- Bronze → Silver: Databricks (aggregation, cleaning, modeling)
- Silver → Gold: Databricks (business KPIs, data marts)
Libraries used inside Lambda:
- DuckDB: In-memory OLAP engine for fast SQL queries.
- PyArrow: High-performance data format for efficient transfer/conversion.
- delta-rs: Rust/Python library for Delta Lake read/write operations.
DuckDB
DuckDB is an embedded OLAP database engine.
It’s lightweight and works entirely in-memory, making it a great fit for Lambda.
DuckDB is especially powerful for analytical queries and batch ETL workloads.
PyArrow
PyArrow is the Python binding of Apache Arrow.
Arrow provides a fast columnar memory format optimized for data analytics and distributed computing.
PyArrow enables efficient data operations, schema handling, and interoperability across different systems.
delta-rs
delta-rs is a Rust implementation of Delta Lake, with bindings for Python and other languages.
It supports ACID transactions, schema evolution, and time travel.
In Python, it’s available as the deltalake package.
Setting Up Databricks with AWS
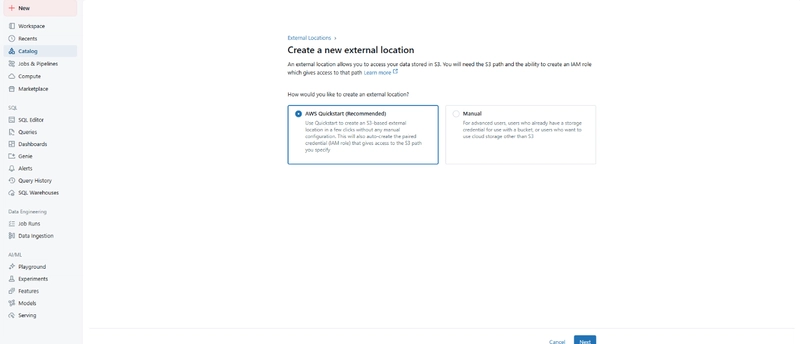
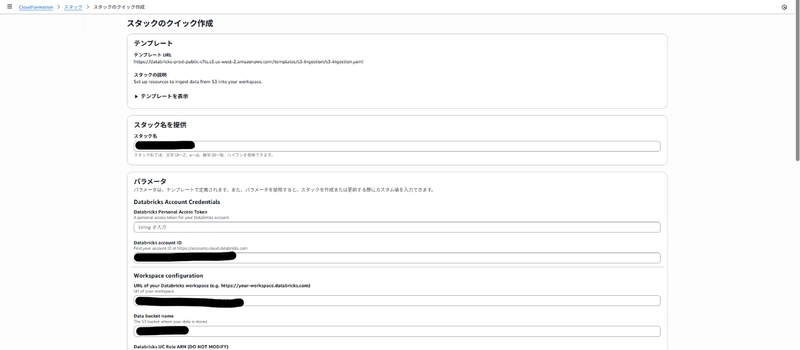
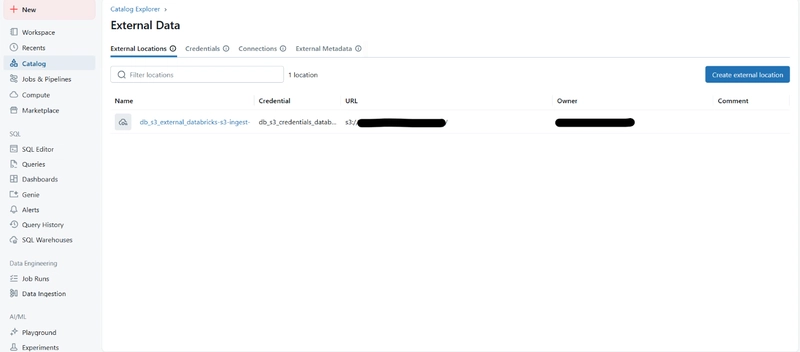
Create an External Location
Choose the AWS quick start option and input your S3 bucket details.
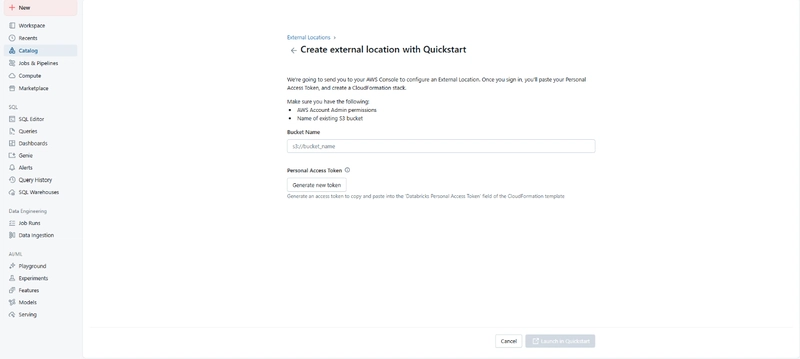
Run CloudFormation
This is automatically executed when creating the external location.
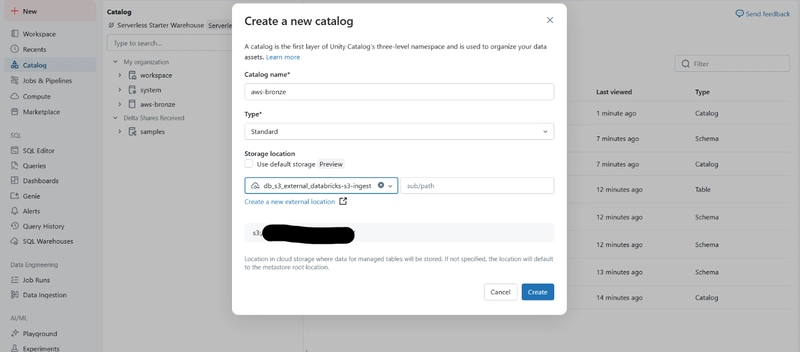
Create a Catalog
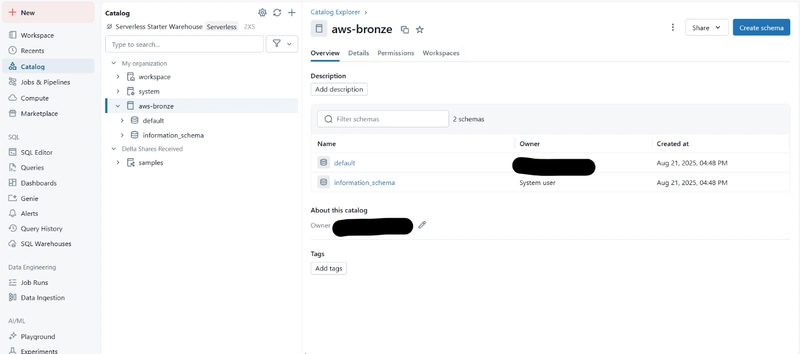
With these steps, Databricks and S3 integration is completed via the GUI.
You can then create and manage tables with simple SQL.
Packaging for Lambda
Since the dependencies are large, I used a container image.
Dockerfile
FROM public.ecr.aws/lambda/python:3.12
WORKDIR /var/task
COPY requirements.txt .
RUN pip install -r requirements.txt --target "${LAMBDA_TASK_ROOT}"
COPY lambda_function.py .
CMD ["lambda_function.lambda_handler"]
requirements.txt
duckdb
pyarrow
deltalake>=1.1.4
Sample Code
import duckdb
import pyarrow as pa
from deltalake import write_deltalake
def lambda_handler(event, context):
try:
duckdb_connection = duckdb.connect(database=':memory:')
duckdb_connection.execute("SET home_directory='/tmp'")
duckdb_connection.execute("INSTALL httpfs;")
duckdb_connection.execute("LOAD httpfs;")
# Get input file from S3 event
s3_bucket = event['Records'][0]['s3']['bucket']['name']
s3_key = event['Records'][0]['s3']['object']['key']
s3_input_path = f"s3://{s3_bucket}/{s3_key}"
print(f"s3_input_path: {s3_input_path}")
query = f"""
SELECT *
FROM read_parquet('{s3_input_path}')
WHERE VendorID = 1
"""
result_arrow_table = duckdb_connection.execute(query).fetch_arrow_table()
print(f"Row count: {result_arrow_table.num_rows}")
print(f"Schema: {result_arrow_table.schema}")
# --- Convert timestamp columns ---
schema = []
for field in result_arrow_table.schema:
if pa.types.is_timestamp(field.type) and field.type.tz is None:
# tz-naive timestamp[us] → timestamp[ns, tz="UTC"]
schema.append(pa.field(field.name, pa.timestamp("ns", tz="UTC")))
else:
schema.append(field)
new_schema = pa.schema(schema)
result_arrow_table = result_arrow_table.cast(new_schema)
print(f"Schema after conversion: {result_arrow_table.schema}")
# Delta table output path
s3_output_path = "s3://your-bucket"
# Write to Delta Lake
write_deltalake(
s3_output_path,
result_arrow_table,
mode="append", # or "overwrite"
)
print(f"Successfully wrote to Delta table: {s3_output_path}")
except Exception as e:
print(f"Error occurred: {e}")
Important Note: WriterVersion >= 7
If a Delta table has WriterVersion >= 7 and contains timezone-naive timestamps, you’ll hit this error:
Writer features must be specified for writerversion >= 7, please specify: TimestampWithoutTimezone
Workaround:
- Convert
timestamp[us]→timestamp[ns, tz="UTC"]before writing. - Ensure you’re using deltalake >= 1.1.4.
References:
- https://stackoverflow.com/questions/79503015/timestampwithouttimezone-error-on-python-notebook
- https://github.com/delta-io/delta-rs/issues/2631#issuecomment-3163240553
Execution Example
Sample data: NYC Taxi Data (AWS Marketplace)
Lambda triggered via S3:
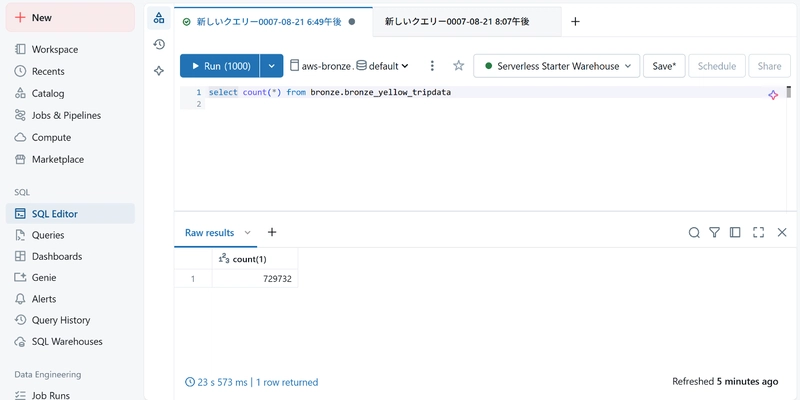
Successfully wrote data into Delta Lake (OTF) format!
Beyond the Bronze Layer
- Bronze → Silver (Databricks): normalization, joins, aggregation, data quality checks, schema modeling.
- Silver → Gold (Databricks): business KPIs, data marts, BI/ML-ready datasets.
Example workflow responsibilities:
| Step | Tool | Notes |
|---|---|---|
| Landing → Bronze | Lambda / DuckDB / delta-rs | Cost-efficient, Delta format on S3 |
| Bronze → Silver | Databricks | Heavy transforms, modeling, integration |
| Silver → Gold | Databricks | Business metrics, BI/ML-ready outputs |
Pros and Cons
Pros
- Cost-efficient: No Glue, EMR, or heavy Databricks jobs for preprocessing.
- Easy development with Lambda + Python libraries.
- SQL-based (PostgreSQL-like syntax).
- Efficient in-memory processing (DuckDB).
- Real-time ETL with S3 triggers.
Cons
- Lambda memory limit (10 GB max).
- 15-minute execution limit (not ideal for very large datasets).
- May require alternative compute (e.g., ECS/Fargate) for scaling.
Conclusion
We explored how to use AWS Lambda + DuckDB + delta-rs for a lightweight ETL pipeline into Delta Lake.
Databricks is powerful but can be expensive for preprocessing workloads that don’t require heavy compute.
By offloading Landing → Bronze ETL into Lambda, you can achieve:
- Lower costs
- Real-time ingestion (via S3 triggers)
- A simpler and more flexible pipeline
This approach is particularly useful for small-to-medium datasets or preprocessing steps.
I hope this article helps if you’re considering Delta Lake with lightweight ETL on AWS.

