Small Language Models: A better way to Agentic AI
AI agents are gaining serious momentum. But there’s a catch: most of these agents rely on large language models (LLMs). These models don’t come cheap. They run on massive cloud infrastructure, burn through GPU cycles, and rack up costs fast, and tend to generate very little revenue per token, which makes the economics even harder.
That’s where small language models (SLMs) come in.
In this post, we’ll explore why SLMs are becoming a game-changer for agentic AI. They’re lighter, faster, more cost-effective, and just right for the kinds of tasks agents are designed to perform. With native support for edge computing, they are often a better match for privacy-preserving computation and a more viable path toward realizing the vision of a “Society of AI Agents.”
What You’ll Learn in This Post
- What Are SLMs?
- LLMs vs. SLMs:
- Why are SLMs a natural fit for AI agents?
- Why are SLMs a viable path to a decentralised compute environment?
- Why is the industry still stuck on LLMs?
- How to transition from LLMs to SLMs for agent-based systems?
- SLMs in Practice: Coral Agents on the GAIA Benchmark
What Are SLMs?
SLMs are compact and efficient language models with parameters from a few million up to a few billion, as opposed to LLMs with hundreds of billions or even trillions of parameters.
SLMs are designed to be:
- Efficient
- Task-specific
- Deployable on low-cost hardware (even laptops and phones)
Example: DistilBERT, GPT-4o mini, Granite, Ministral, Phi
LLMs vs. SLMs:
| Aspect | LLMs | SLMs |
|---|---|---|
| Architecture | Deep, complex networks with multiple layers and huge parameter counts | Smaller networks with fewer layers and parameter count |
| Training Data | Massive, general-purpose | Task-specific or domain-focused datasets |
| Compute Needs | High-end GPUs or TPUs required | Can run on laptops or edge devices |
| Deployment | Typically cloud-only | Local, on-device, or on-prem possible |
| Latency | High (due to cloud roundtrips) | Sub-500ms achievable |
| Cost | Expensive | 10–30 times cheaper |
LLMs are powerful, no doubt. But when you’re running agents that need to act quickly, cheaply, and reliably, SLMs hit the sweet spot.
Why are SLMs a natural fit for AI Agents?
Agentic systems break tasks into subtasks. That’s how they work — searching, summarizing, extracting data, and taking actions. And most of these subtasks? They don’t need the full force of an LLM.
Let’s walk through why SLMs are a natural fit for agents.
1. SLMs Are Already Good Enough
Today’s 3 to 7 billion parameter models are surprisingly strong at routine tasks — summarizing, classifying, and extracting structured data. You don’t need a 70B parameter beast just to decide if an email is spam or not.
2. They’re Way Cheaper to Run
LLMs are resource hogs. SLMs can run on standard hardware, even on-device. That saves you serious compute cost and removes your dependency on expensive cloud APIs.
3. Predictability > Creativity
For agents, you want consistent, stable outputs. SLMs tend to be more predictable and deterministic, which is exactly what you want for tasks like extracting order numbers or validating structured inputs.
4. Modular Agent Design Becomes Possible
Instead of relying on one giant LLM to handle everything, you can split the work. Use small, fine-tuned models for each subtask and only call a big model when necessary.
5. Agents Generate Training Data for Free
Agents constantly produce useful data; every prompt, reasoning step, and tool call can be logged and reused. This makes it easy to fine-tune SLMs on real-world tasks, creating a feedback loop: agents train SLMs, and SLMs improve agents.
Why are SLMs a viable path to a decentralised compute environment?
When the goal is efficient, low-latency, and scalable AI in a decentralized compute environment, SLMs are typically more practical and performant than LLMs. LLMs are preferred only if generality and complexity are more important than speed, cost, and privacy
SLM vs LLM for Decentralized Compute
| Factor | SLM | LLM |
|---|---|---|
| Resource Demand | Low | High |
| Deployment | Edge/local/decentralized | Cloud/centralized |
| Cost/Energy | Low | High |
| Speed | Fast | Slower (in distributed settings) |
| Data Privacy | On-device processing possible | Requires sending data to cloud |
| Best For | Domain-specific, real-time, private | Open-ended, creative, general tasks |
Democratization and Governance
SLMs make participatory AI feasible, letting communities or DAOs own, govern, and improve their models. This contrasts with LLMs, which are typically controlled by centralised companies.
Additional Point:
Today, there are several decentralized compute networks tailored for AI. Each platform is built using Trusted Execution Environments (TEEs), Zero‑Knowledge Proofs (ZKPs), or a combination of technologies like Multi-party Computation(MPC), Fully Homomorphic Encryption (FHE), or even federated learning(FL).
Compared with small language models (SLMs), performing these privacy-preserving operations on large language models (LLMs) is significantly more computationally intensive.
Privacy, Security, and Edge AI
As SLMs are compact, they can run locally, even on mobile or edge devices. That means no personal data has to leave the device. Perfect for healthcare, finance, or legal settings.
You can combine SLMs with:
- Zero-knowledge proofs (ZKPs): Allow one party to prove to another party that they know a value or performed a computation without revealing the actual data.
- Federated Learning(FL): Allows training an AI model across multiple devices while keeping both data and model updates local to each device. Only the model’s weight updates are shared for aggregation into a global model
- Fully homomorphic encryption (FHE): Allows computations to be performed directly on encrypted data
- Trusted Execution Environments (TEEs): Ensure code and data stay protected during execution by creating a secure area within the processor that is isolated from the OS
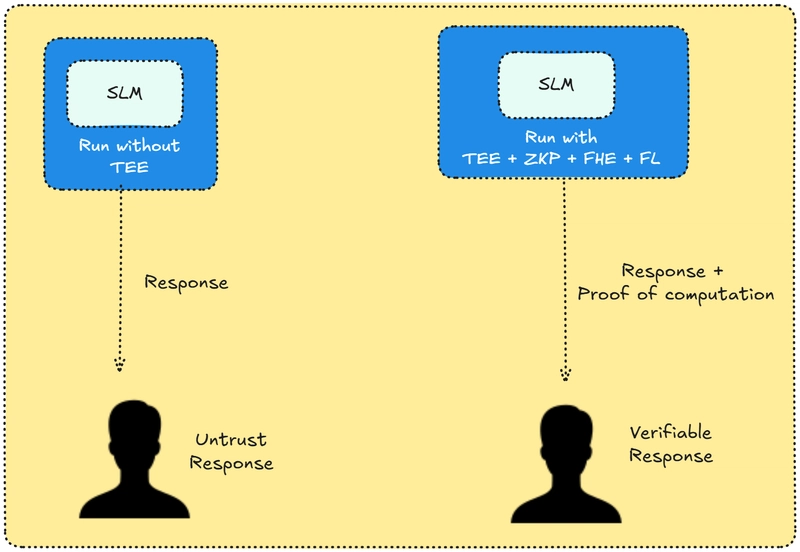
This enables a new level of privacy and security: your agent can compute, reason, and even prove its reasoning without ever exposing sensitive inputs.
Examples of Privacy-preserving AI Infrastructure:
The infrastructure for such privacy-preserving AI is already being developed by several organizations, creating the foundation that could support efficient SLM deployment:
1. GPU TEE for Confidential AI by Phala Network:
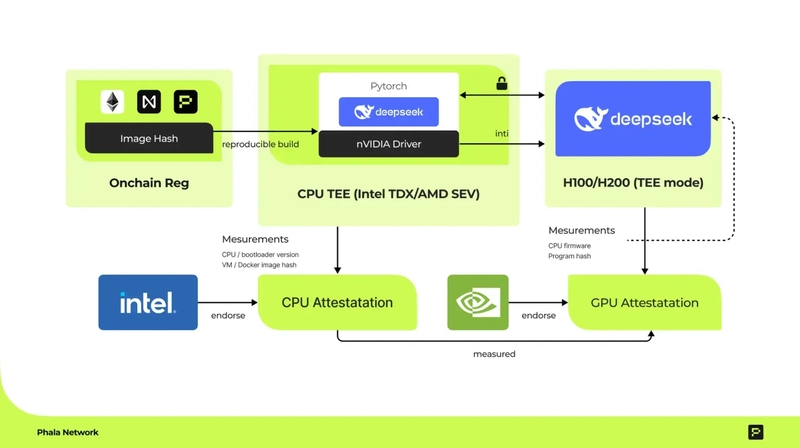
Reference: https://phala.network/posts/gpu-tee-is-launched-on-phala-cloud-for-confidential-ai
2. ZKML Framework by Bionetta:
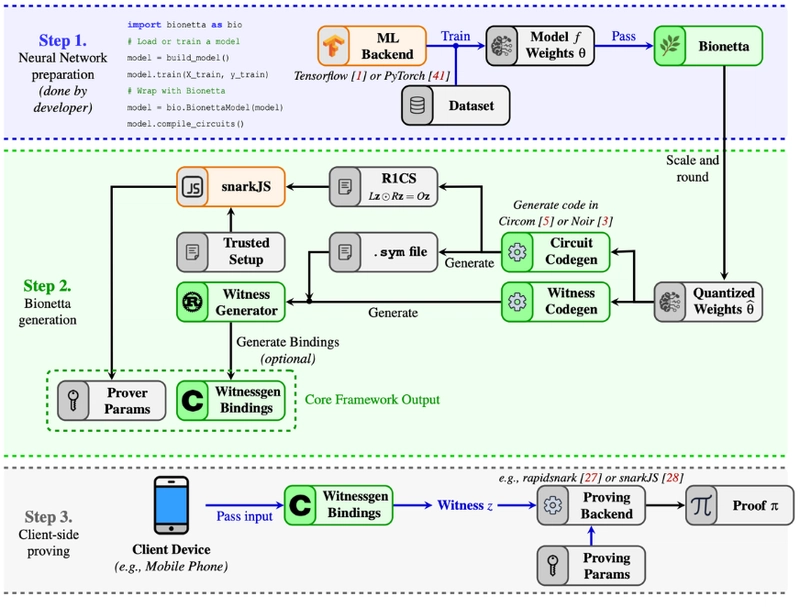
Reference: https://docs.rarimo.com/zkml-bionetta/
3. Federated Learning on Blockchain by Flock.io:
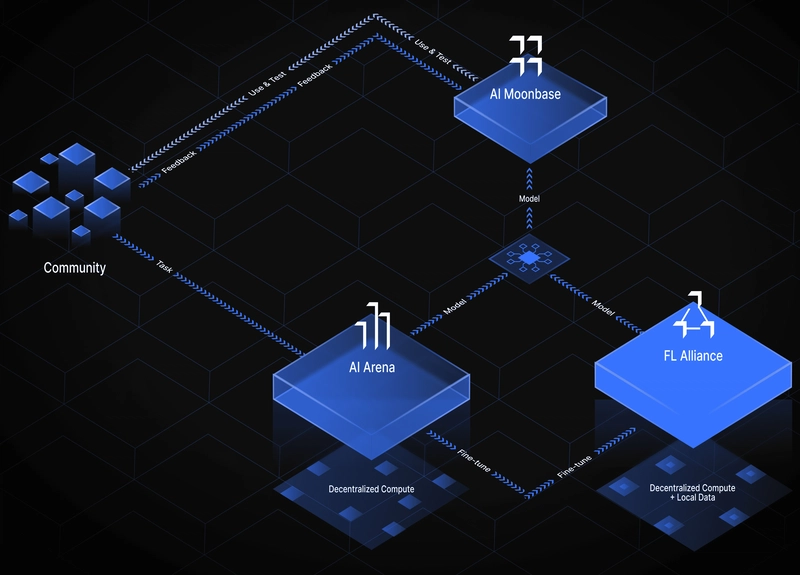
Reference: https://docs.flock.io/what-is-flock/architectural-breakdown/system-design
Many more organizations like Acurast Network, Secret Network are working in the same direction. While these platforms currently focus primarily on LLMs, their underlying privacy-preserving technologies (TEE, ZKP, federated learning) are even more practical and cost-effective when applied to SLMs due to their lower computational requirements.
Why is the Industry still stuck on LLMs?
Despite all the above, many companies stay locked into the LLM paradigm. Why? Three big reasons:
1. Deep Investment and Vendor Lock-In
Billions have been spent on LLM-focused infrastructure. Cloud platforms, GPU clusters, and inference APIs were all built with big models in mind. Switching to many small models means rethinking architecture — and that’s not easy.
2. Misleading Benchmarks
Most public model evaluations use general-purpose tests like MMLU or BigBench. These favor large models. But agents mostly perform narrow, repetitive tasks, and on those, SLMs often perform just as well. The nuance gets lost.
3. Hype and Media Bias
The headlines still chase the biggest model numbers(500B parameters, 1T tokens). That kind of hype pulls attention and funding away from smaller, more practical models. Meanwhile, open-source SLMs keep improving quietly in the background.
How to Transition from LLMs to SLMs in Your Agent Stack
If you’re ready to go from theory to practice, here’s how to do it — step by step.
Step 1: Start Logging Everything
Track prompts, intermediate reasoning steps, tool usage, and final outputs. This gives you real-world training data straight from your agents. Anonymize it. Store it securely.
Step 2: Clean and Filter the Data
Scrub out sensitive content. Keep only high-quality, useful samples. Build up 10K to 100K examples per task. That’s enough to fine-tune an effective SLM.
Step 3: Cluster by Task Type
Group similar interactions. Are you seeing lots of summarizing? Entity extraction? Classification? Each cluster represents a potential fine-tuning opportunity.
Step 4: Pick the Right SLM
Choose a base model for each task. Look at the license type, performance, and hardware requirements. For many jobs, 3B to 7B models are ideal.
Step 5: Fine-Tune Per Task
Use LoRA, QLoRA, or even full fine-tuning if needed. Most tasks don’t need massive computing. A few GPU hours on an A100 can go a long way.
Step 6: Deploy, Monitor, Improve
Swap in your SLMs. Track performance. Keep logging and improving. Fine-tune again as needed.
SLMs in Practice: Coral Agents on the GAIA Benchmark
To ground the ideas discussed above in real-world results, we demonstrated that SLM-powered agents can beat the results of LLM-enabled agents.
Coral GAIA is a modular multi-agent framework inspired by CAMEL’s OWL. It features a suite of specialized agents, each designed for discrete tasks. A key design decision in Coral GAIA is its focus on small language models, including GPT-4.1 Mini, rather than large language models.
Goal: Coral allows for agents to scale horizontally by challenging the notion that scaling agents vertically only is optimal
To evaluate this, Coral ran its system against the GAIA Benchmark.
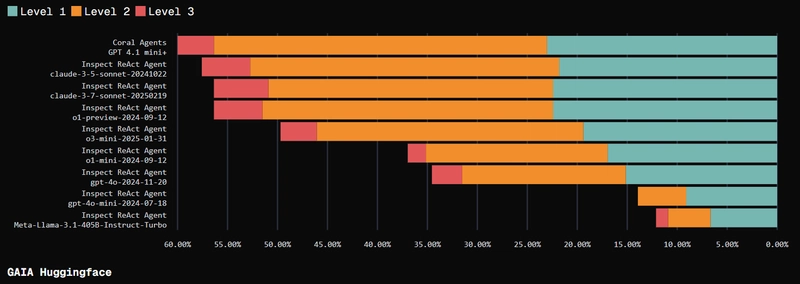
On this benchmark, Coral’s SLM-powered agents outperformed several well-known systems, including those using Claude 3.7, across multiple levels of the evaluation.
This result reinforces several key ideas presented in this blog:
- SLMs are well-suited to agentic workflows where subtasks can be delegated and optimized independently
- Horizontal scaling of agents rather than vertical scaling of models is both viable and effective
- Cost, latency, and privacy constraints can be better addressed using SLMs in modular task-specific configurations
For detailed performance metrics, architectural insights, and full leaderboard comparisons, read the full GAIA Benchmark report here: https://coral-gaia-report.pages.dev/
Conclusion:
AI agents don’t need massive models to be effective. Small Language Models (SLMs) offer the ideal balance of performance, cost, speed, and privacy for real-world agentic systems. They unlock possibilities that LLMs simply can’t: Don’t just scale up, scale smart.
Website: https://www.coralprotocol.org/
X: https://x.com/Coral_Protocol
LinkedIn:https://www.linkedin.com/company/coralprotocol/
GitHub: https://github.com/Coral-Protocol