Compilers and How They Work
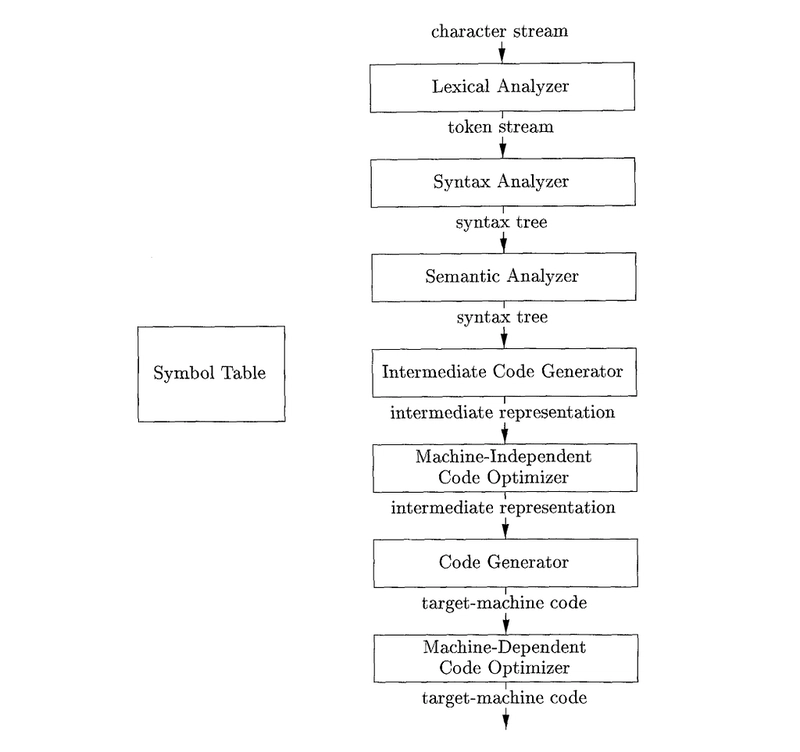
Have you ever wondered how the code you write transforms into a running program? If so, you’re in the right place. A compiler is a powerful tool that translates human-readable source code into assembly language, a medium-level representation that a computer can process. The compilation process involves several crucial steps, including lexical analysis, syntax analysis, semantic analysis, intermediate code generation, code optimization, and code generation.
That’s about the flow of phases during compilation. Let’s dive deep into each phase now.
Lexical Analysis
Lexical analysis is the phase where the source code is broken down into tokens. Tokens include keywords, identifiers, operators, and delimiters. Each token is saved into a data structure called the Symbol Table. Each entry is stored in the following format:
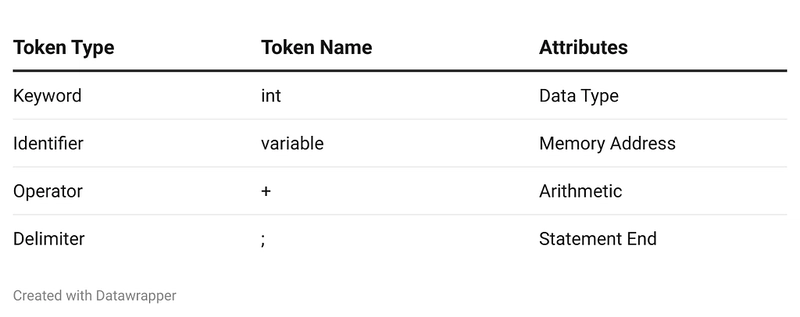
This phase helps in simplifying the source code for further processing.
Syntax Analysis
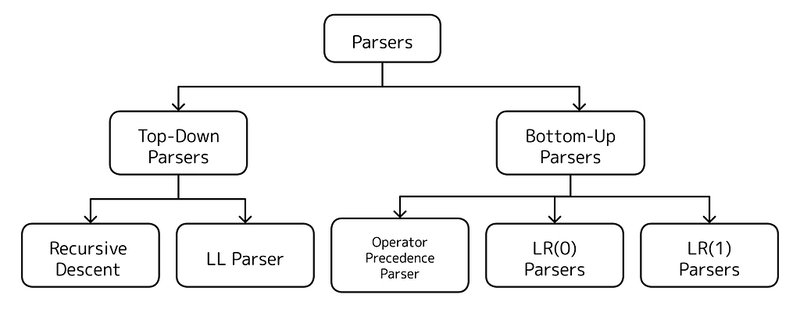
Syntax analysis, also known as parsing, checks whether the sequence of tokens follows the grammatical structure of the programming language. It constructs a parse tree or abstract syntax tree (AST). If there are syntax errors, such as missing semicolons or mismatched brackets, they are detected in this phase. Parsing is performed using a parser, which is classified into two main types.
For example, given the expression:
int a = 10 + 5;
A parser would check if this follows the correct syntax of variable declaration and assignment.
Semantic Analysis
Semantic analysis ensures that the parsed statements are logically and meaningfully correct according to the language rules. It verifies aspects such as type compatibility, function calls, scope resolution, and variable declarations. This phase detects errors that cannot be caught during syntax analysis, such as type mismatches and undeclared variables.
For example, consider the following statement:
int a = "Hello"; // Type mismatch error
Although this statement is syntactically correct, it is semantically incorrect because an integer variable (a) cannot hold a string value.
The semantic analyzer performs tasks such as:
- Type Checking: Ensuring variables and expressions follow proper type rules.
- Scope Resolution: Validating that variables and functions are used within their declared scope.
- Function and Operator Overloading Checks: Ensuring correct function or operator usage.
- Array and Pointer Validation: Verifying array bounds and pointer dereferencing.
By enforcing these rules, semantic analysis helps prevent logical errors before the code proceeds to the next stage of compilation.
Intermediate Code Generation
Once semantic analysis is completed, an intermediate representation (IR) of the source code is generated. This representation is independent of the target machine, making it easier to optimize and translate into machine code. IR is typically in the form of three-address code (TAC), abstract syntax trees, or static single assignment (SSA) form.
Here’s an example of Three-Address Code (TAC) for the expression:
a = b + c * d;
TAC representation:
T1 = c * d // Multiplication is computed first
T2 = b + T1 // Addition is performed
a = T2 // Assign the result to 'a'
Here, T1 and T2 are temporary variables used to break down the expression into simpler operations. This makes it easier for the compiler to optimize and generate machine code efficiently.
Code Optimization
Optimization improves the efficiency of the generated code by reducing execution time and memory usage. Code optimizations can be categorized into two types:
Platform-Independent Optimization
These optimizations are performed at the intermediate code level and do not depend on the target machine architecture. Examples include:
- Constant folding: 10 + 5 is replaced with 15.
- Loop unrolling: Reducing loop iterations to enhance speed.
- Dead code elimination: Removing unused variables or unreachable code.
- Common subexpression elimination: Identifying and reusing repeated expressions.
For example:
int x = 5;
int y = 10;
x = y * 0; // Dead code, as x is assigned 0 anyway
The compiler removes redundant operations to enhance performance.
Platform-Dependent Optimization
Platform-dependent optimizations are tailored to the target machine’s architecture, leveraging hardware-specific features for improved performance. Some widely used techniques include:
- Register Allocation: Allocating frequently used variables to CPU registers to reduce memory access latency.
- Instruction Scheduling: Reordering instructions to avoid pipeline stalls and improve execution speed.
- SIMD (Single Instruction, Multiple Data) Utilization: Leveraging vectorized instructions to process multiple data points in parallel.
Example: Optimizing Code for Different Architectures
Consider the simple arithmetic operation:
int a = 10 + 5;
The generated assembly code for an x86 processor might be:
MOV EAX, 10
ADD EAX, 5
MOV a, EAX
For an ARM processor , the equivalent instructions could be:
MOV R0, #10
ADD R0, R0, #5
STR R0, [a]
By utilizing processor-specific features like SIMD instructions (SSE/AVX for x86, NEON for ARM) or loop unrolling for vector processing, compilers can significantly enhance execution efficiency.
Code Generation
Finally, the optimized intermediate code is translated into machine code that can be directly executed by the processor. This step is crucial as it converts the platform-independent representation into an architecture-specific instruction set. Code generation involves several sub-processes:
- Register Allocation: Assigning variables and temporary values to CPU registers for efficient execution.
- Instruction Selection: Mapping high-level operations to the most efficient low-level machine instructions.
- Memory Management: Handling stack, heap, and global memory allocations properly.
- Assembly Code Generation: Producing platform-specific assembly instructions before final machine code translation.
For example, given the statement:
int a = 10 + 5;
The compiler generates equivalent assembly instructions:
MOV R1, 10 ; Load value 10 into register R1
ADD R1, 5 ; Add 5 to the value in R1
MOV a, R1 ; Store the result in variable 'a'
On a different processor architecture, the instructions might look slightly different due to variations in instruction set architectures (ISAs) such as x86, ARM, or RISC-V.
After generating assembly code, the compiler invokes an assembler to convert it into machine code, resulting in an executable binary file. This final compiled program can then be loaded into memory and executed by the operating system.
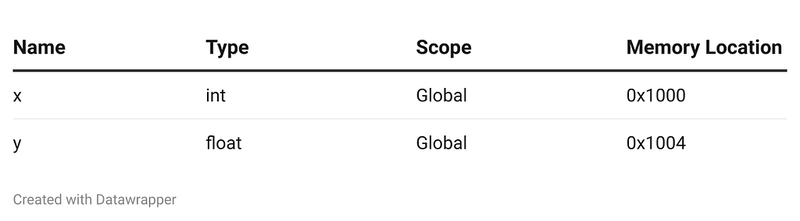
Symbol Table
The Symbol Table is a crucial data structure used throughout the compilation process. It stores all identifiers (variable names, function names, object names) and their attributes, such as data type, scope, and memory location. The symbol table helps in:
- Efficient lookup: Quickly finding variable details.
- Scope management: Ensuring that variables are used within their declared scope.
- Type checking: Preventing invalid type assignments.
- Optimization support: Assisting in redundant code elimination and memory allocation.
For example, the symbol table for the following code:
int x = 10;
float y = 5.5;
Would look like:
Error Handling in Compilation
Errors can occur at different stages of compilation, and a compiler must handle them efficiently. The Error Handler identifies, reports, and recovers from errors to continue compilation smoothly. Errors are broadly categorized as:
- Lexical errors: Mistyped keywords or invalid characters.
- Syntax errors: Missing semicolons, unmatched brackets.
- Semantic errors: Type mismatches, undefined variables.
- Runtime errors: Divide by zero, memory overflow.
For example, in the following code:
int x = 10
printf("x = %d", x);
The missing semicolon (;) will result in a syntax error. The compiler will report:
error: expected ';' before 'printf'
An efficient compiler attempts error recovery by:
- Panic mode recovery: Skipping to the next valid token.
- Phrase level recovery: Inserting or deleting tokens to maintain syntax.
- Error production recovery: Suggesting corrections.
Conclusion
Compilers play a crucial role in converting human-readable code into machine-executable instructions. Understanding the phases of compilation helps developers write better and more optimized code. Whether it’s handling syntax, optimizing performance, managing symbols, or detecting errors, each phase contributes to making the final executable efficient and error-free.