Why Not Implement HMR with Static Analysis?
A few months ago, I came across an article called How to build Hot Module Replacement in Python, which talked about using their Python static analysis tool Tach to generate a dependency graph in a key-value format like this:
{
"a.py": ["b.py", "c.py"],
"b.py": ["d.py"],
"d.py": ["e.py"],
"c.py": ["f.py"]
}
By the way, this project became unmaintained last month 😅. I only found out after asking that the developer left to start an AI company. I think someone in the comments put it well:
I guess that’s the issue with open source tools being backed by VCs. These tools will never be maintained if you can’t make tons of money off of them.
The basic idea is that whenever a file changes, you use the dependency graph to update (i.e., re-import) that file and all the modules it directly or indirectly affects.
The Problem
Python developers usually don’t like splitting files too finely, so in practice, using this approach often means that a lot of files get reloaded each time (sometimes, changing any file could trigger a reload of every module in the project). Compared to a regular cold reload, this solution only saves the time spent importing third-party libraries and the overhead of starting Python itself. But you still lose all intermediate state.
On top of that, lazy loading and dynamic imports can’t be captured by static analysis.
Our Runtime Solution
hmr takes a completely different approach by recording dependencies at runtime. Unlike tach, which uses static analysis of the AST to determine dependencies, hmr tracks which modules are imported and which variables from those modules are actually used, building the dependency graph that way.
For example, suppose you have a file data.py:
a = 1
b = 2
c = a + b # 3
And another file a.py uses a value from data.py:
from data import a
print(a)
With static analysis, a.py would be considered dependent on data.py, so if data.py is reloaded, a.py would be reloaded too.
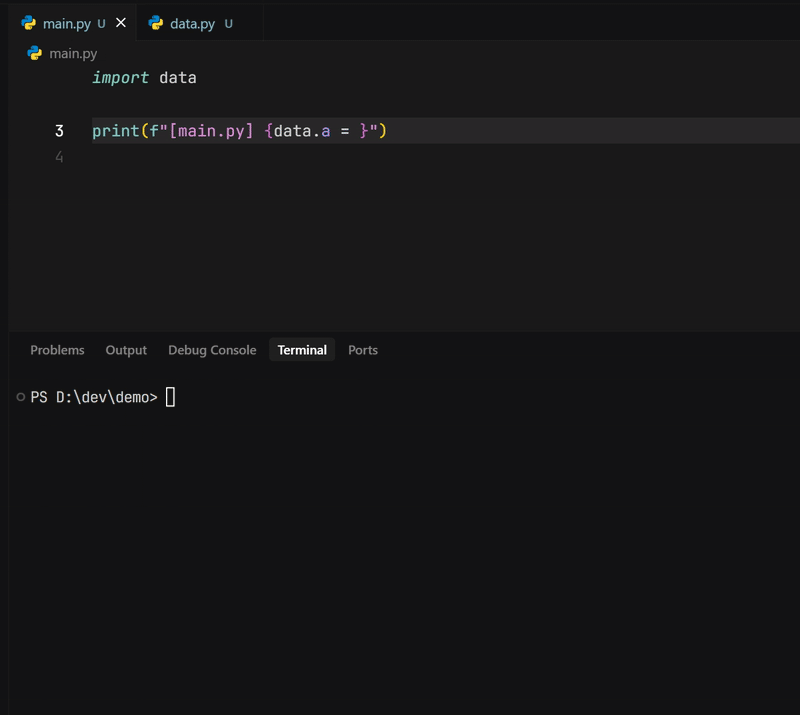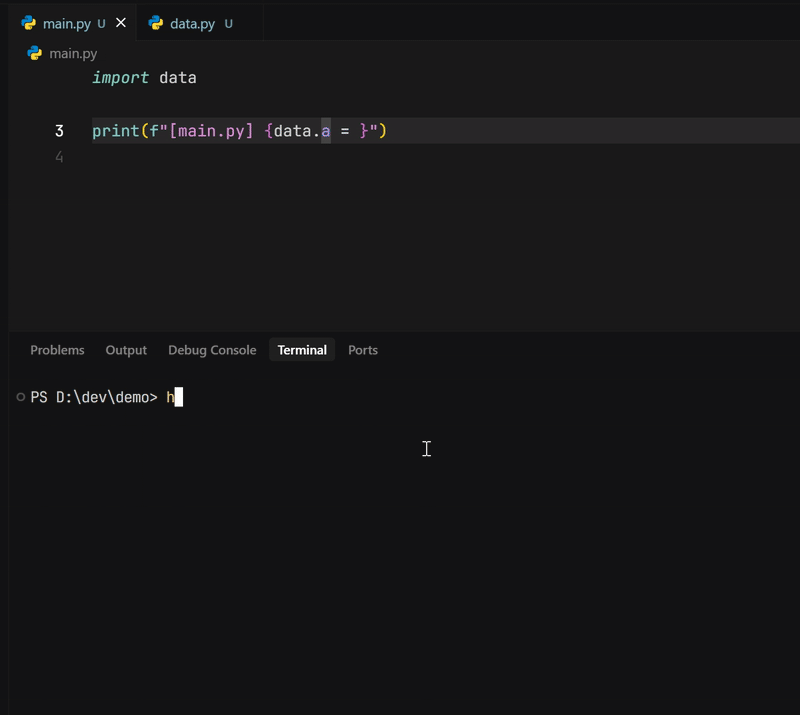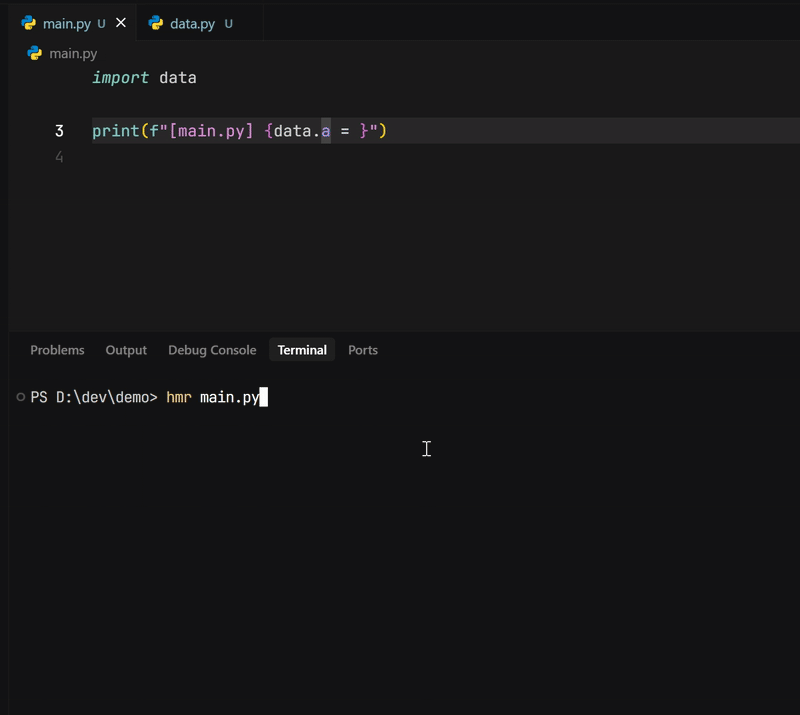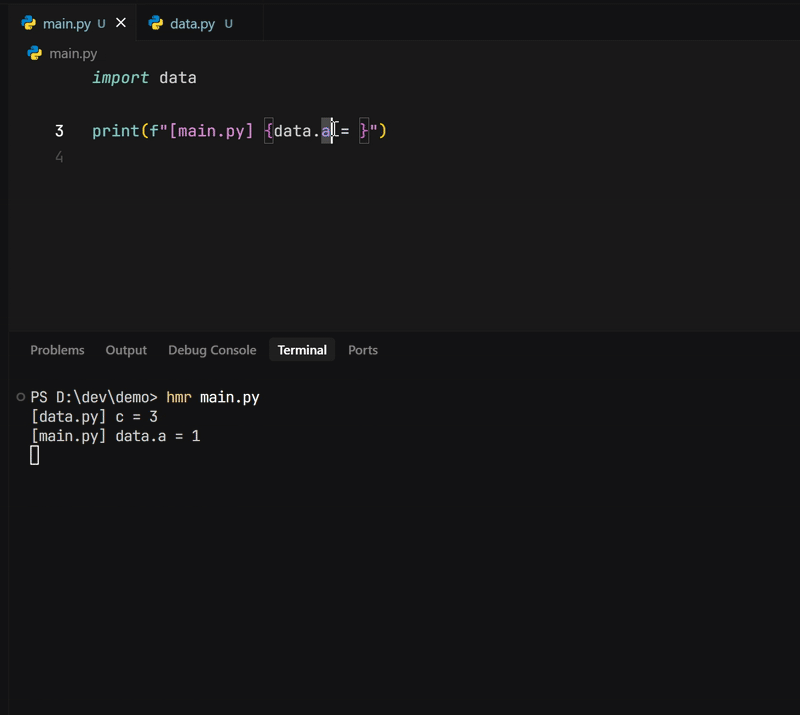
But with hmr, we support much finer-grained reactivity. That means a.py is only considered dependent on the value of a in data.py. So if you change b = 2 to b = 3 in data.py, the value of data.a hasn’t changed, so a.py won’t reload.
Only if you change a = 1 to something else will a.py be triggered to reprint the value of a. Similarly, if your entry file is c.py like this:
import data
print(data.c)
Then changing either a or b (as long as the result of a + b changes) will cause c to change, and data.c will be reprinted.
This is the kind of fine-grained hot reloading that static analysis can never achieve.
How It Works
It’s actually pretty simple. Basically, I just need to record every time a module’s __getattr__ is accessed. For example, if module a triggers b.__getattr__("c"), that means somewhere in a.py there’s a from b import c or b.c, so module a depends on b.c.
As for how to customize a module’s __getattr__, it’s just regular metaprogramming (I explained this in detail in this article). In short, you implement a custom subclass of ModuleType and register a ModuleFinder in sys.meta_path.
Conclusion
After more than half a year of work, I’ve handled tons of edge cases and solved many performance issues, all to make sure the magic works transparently and users never have to worry about the dragons under the hood.
Now, hmr as a CLI fully mimics Python’s behavior. For example, if you usually start your app with python main.py -a --b c, you can just switch to hmr main.py -a --b c and everything should just work.
If you use Uvicorn to start a web service, you can also try uvicorn-hmr, which is a drop-in replacement for uvicorn --reload—just swap the command and you’re good to go. I’ve been very careful about backward compatibility.
The package names match the CLI names: for example, hmr is installed with pip install hmr, and uvicorn-hmr with pip install uvicorn-hmr.
Recently, I also made a fun and even more hacky tool called hmr-daemon. After pip install hmr-daemon, you don’t need to change any code, but whenever you modify a file and the Python process hasn’t exited yet, that module will be reloaded, along with any affected modules in the correct order. This is especially useful when you’re using your project’s modules in a REPL like ipython.


