Guide to get started with Retrieval-Augmented Generation (RAG)
🔹 What is RAG? (in simple words)
Retrieval-Augmented Generation (RAG) combines:
- Search (Retrieval) → find relevant information from your data
- Generation → let an LLM generate answers using that data
👉 Instead of guessing, the AI looks up facts first, then answers.
🧠 Why RAG is important
- Reduces hallucinations
- Answers from your own data (PDFs, docs, DBs, APIs)
- Keeps data up-to-date (no retraining needed)
- Perfect for chatbots, internal tools, search, Q&A
🧩 RAG Architecture (high level)
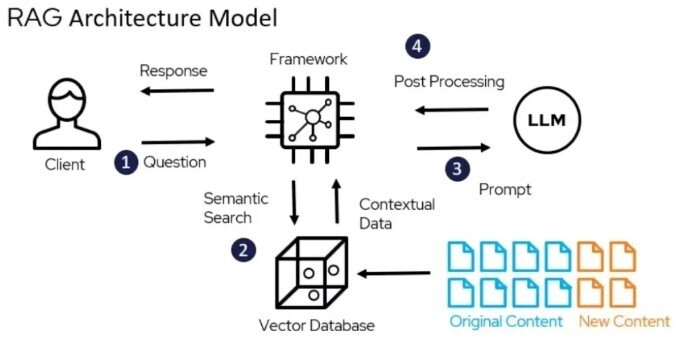
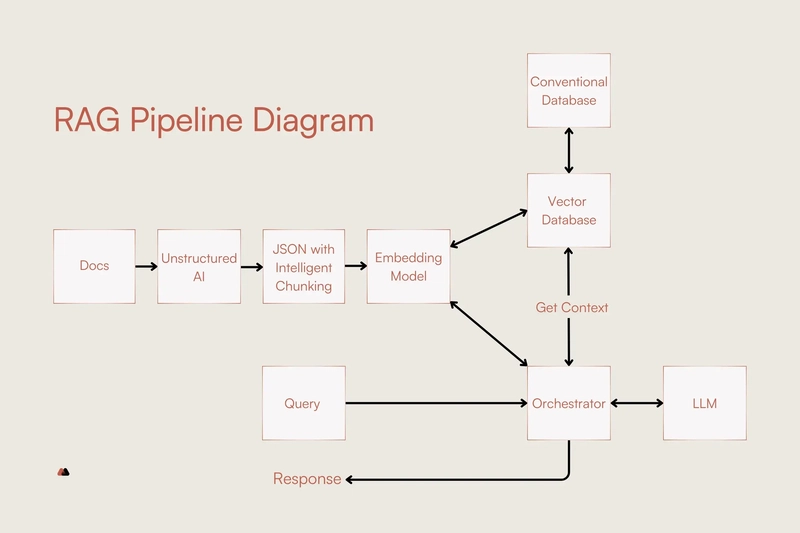
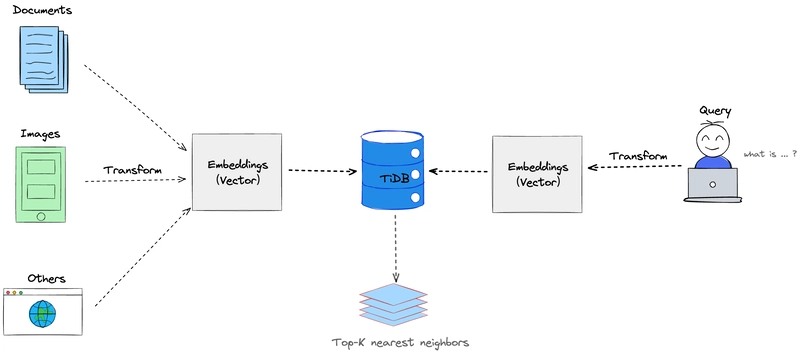
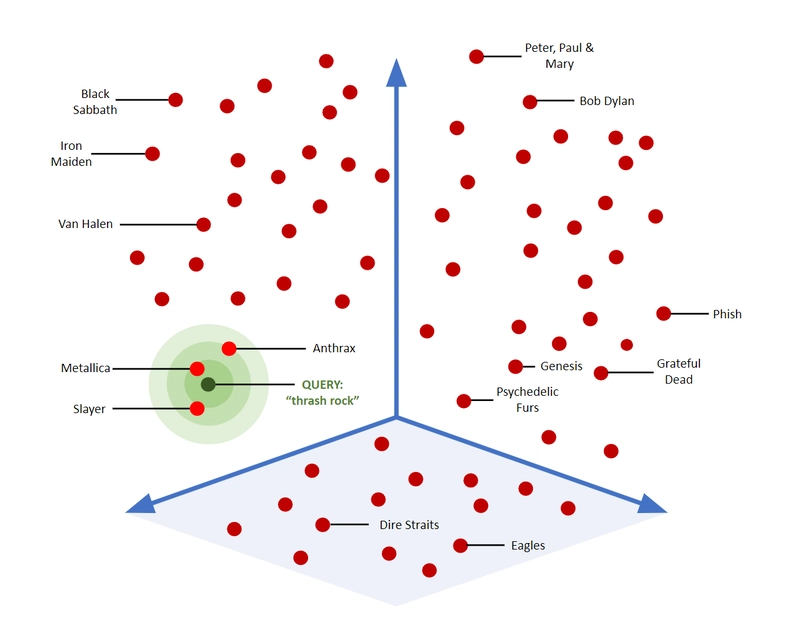
Flow:
- User asks a question
- Relevant documents are retrieved
- Retrieved context is sent to LLM
- LLM generates an answer grounded in data
🛠️ Core Components of RAG
1️⃣ Data Source
- PDFs
- Word files
- Markdown
- Databases
- APIs
- Websites
2️⃣ Embeddings
Text → numerical vectors for similarity search
Popular models:
- OpenAI embeddings
- SentenceTransformers
3️⃣ Vector Database
Stores embeddings for fast search:
- FAISS (local)
- Pinecone
- Weaviate
- Chroma
4️⃣ LLM (Generator)
Examples:
- GPT-4 / GPT-4o
- Claude
- Llama
⚙️ Minimal RAG Setup (Beginner)
Step 1: Install dependencies
pip install langchain faiss-cpu openai tiktoken
Step 2: Load & embed documents
from langchain.document_loaders import TextLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
loader = TextLoader("data.txt")
docs = loader.load()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(docs, embeddings)
Step 3: Retrieve + generate answer
query = "What is RAG?"
docs = db.similarity_search(query)
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
response = llm.predict(
f"Answer using this context:n{docs}nnQuestion:{query}"
)
print(response)
🎉 That’s a working RAG system
🧪 What RAG is used for (real examples)
- 📄 PDF Chatbots
- 🏢 Internal company knowledge base
- 🧑⚖️ Legal document search
- 🩺 Medical guidelines assistant
- 💻 Developer documentation bots
⚠️ Common beginner mistakes
❌ Stuffing too much text into prompt
❌ Not chunking documents
❌ Using wrong chunk size
❌ Skipping metadata
❌ Expecting RAG to “reason” without good data
✅ Best practices (Day-1)
- Chunk size: 500–1000 tokens
- Add source citations
- Use top-k retrieval (k=3–5)
- Keep prompts explicit: “Answer only from context”
🚀 Next steps (recommended)
- Add document chunking
- Use metadata filtering
- Add citations
- Use hybrid search (keyword + vector)
- Add reranking
🧠 When NOT to use RAG
- Math-heavy reasoning
- Code generation without context
- Creative writing
- Pure chatbots
AI with graphs 15 april conf
https://neo4j.registration.goldcast.io/events/d11441d0-5a74-463d-ab1d-22f03c939c3c
https://sessionize.com/nodesai2026/

